Q&A¶
ここでは講義中に出た質問に対する回答を載せていきます。随時更新です。
Week1¶
-
xcodeでも大丈夫か?
- 大丈夫です
-
講義のレコーディングはするか?
- しません。演習講義なので、当日に直接参加してください。ただし、内容はすべてこのウェブページに書いてありますので、C言語がもう全部わかるという人はこのウェブページを読んで宿題だけ出してくれればOKです。
-
Safariでrepl.itで英字入力ができない
- どうやらsafariとrepl.itは相性が悪いようです。Chromeを使うか、ローカルでプログラミングをしてください。
-
Visual Studioでもいいか?
- VSが得意なのであれば、それでもOKです。宿題はVSでもできます。ただし、Linuxのコマンド処理などはVSではできないので、便宜repl.itを参照してください。
-
repl.itでclangを使うのか?
- repl.itでgccを使います。「実行」ボタンを押すとclangが実行されるかもしれませんが、そうではなくgccを直接タイプしてください。ただし、本講義の範囲ではclangもgccも特に変わりはありません。
-
repl.itのアカウント登録時、GitHubアカウントで登録、Googleアカウントで登録、メール登録、があるがどれにすべきか?
- どれでもOKです。
-
repl.itとGitHub連携をして、GitHubの学生プランを使えば、privateにファイルを作れるのではないか?
- その通りです。GitHubにはGitHub Student Developer Packというものがあり、これに登録(無料)すると様々な恩恵が得られます。これに申し込んでもいいです。むしろ、申し込むとかなりお得です。repl.itとGitHubを連携させることで、repl.itでも無料でプライベート領域を作れるようになります。ただし、学生証の写真をGitHub側に送信する必要があり、また一週間以上待つかもしれないので、ちょっとめんどくさいです。なので、今回はこの学生プランを皆さんに強制することはありません。
-
一つ上のディレクトリに移動するときは
$ cd ..で移動できますが、一個下に行く便利な方法はありますか?- 下にいくときはディレクトル名を書かないとダメです。ただ、
$ cd -とすると、自分が直前にいた場所にもどることができます
- 下にいくときはディレクトル名を書かないとダメです。ただ、
-
ディレクトリを移動しなくても中を見れますか?
$ ls dir1/dir2のような書き方で見れます。
-
touchで、カレントディレクトリ以外の場所にtouchでファイルを作成できますか?$ touch dir1/hoge.cのような書き方で出来ます
-
/homeと同じ階層でディレクトリやファイルを作ることができないのはなぜですか?- それらのようなシステムに近いファイルは、ユーザが自由に読み書きを出来ない設定になっています。これは
$ ls -alで確かめられます。たしかめられます。パーミッションでぐぐってみるといいです。
- それらのようなシステムに近いファイルは、ユーザが自由に読み書きを出来ない設定になっています。これは
-
ファイルを作るときに形式を明示しないと、何のファイルになりますか?
touchで作るときは、形式という概念はありません。全て無のファイルです。(hoge.mp4にしようが、hoge.jpgにしようが、無です)
-
a.outのバイナリ列を読む方法はありますか?
odコマンドで見れます
-
GUIアプリケーションをコマンドラインから開けるか?
- 例えばローカルでUbuntuの場合は、
$ evince hoge.pdfでpdfビューアが起動したりします。しかしrepl.itではGUIアプリケーションは使えません。
- 例えばローカルでUbuntuの場合は、
-
includeの行を消してもコンパイルされるのはなぜですか?
- コンパイラが気を利かせてincludeしなくてもコンパイルできるようになっているようです。次のコマンドでコンパイルするとエラーになります
$ gcc -Werror-implicit-function-declaration main.c
- コンパイラが気を利かせてincludeしなくてもコンパイルできるようになっているようです。次のコマンドでコンパイルするとエラーになります
-
macのlocalで、stdio.hはどこにあるか
- 次のようです。環境によっては違うかもしれません。
/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk/usr/include/stdio.h
- 次のようです。環境によっては違うかもしれません。
-
\tのメリットは?スペース4個打つこととの違いは?- 例えば
と打つと、出力は次のようになります
printf("111\t2\n"); printf("1\t2\n");2の位置がそろってくれます。このように、タブは「伸縮して位置を合わせてくれる空白」という意味があります。111 2 1 2
- 例えば
-
WSLで、直接ubuntuを起動する場合と、windows terminalを経由する場合の違いは?
- 同じです。デフォルト設定で比べると、windows terminalのほうが綺麗です。また、windows terminalの場合はタブがついていますので、いくつもウインドウを作れます。
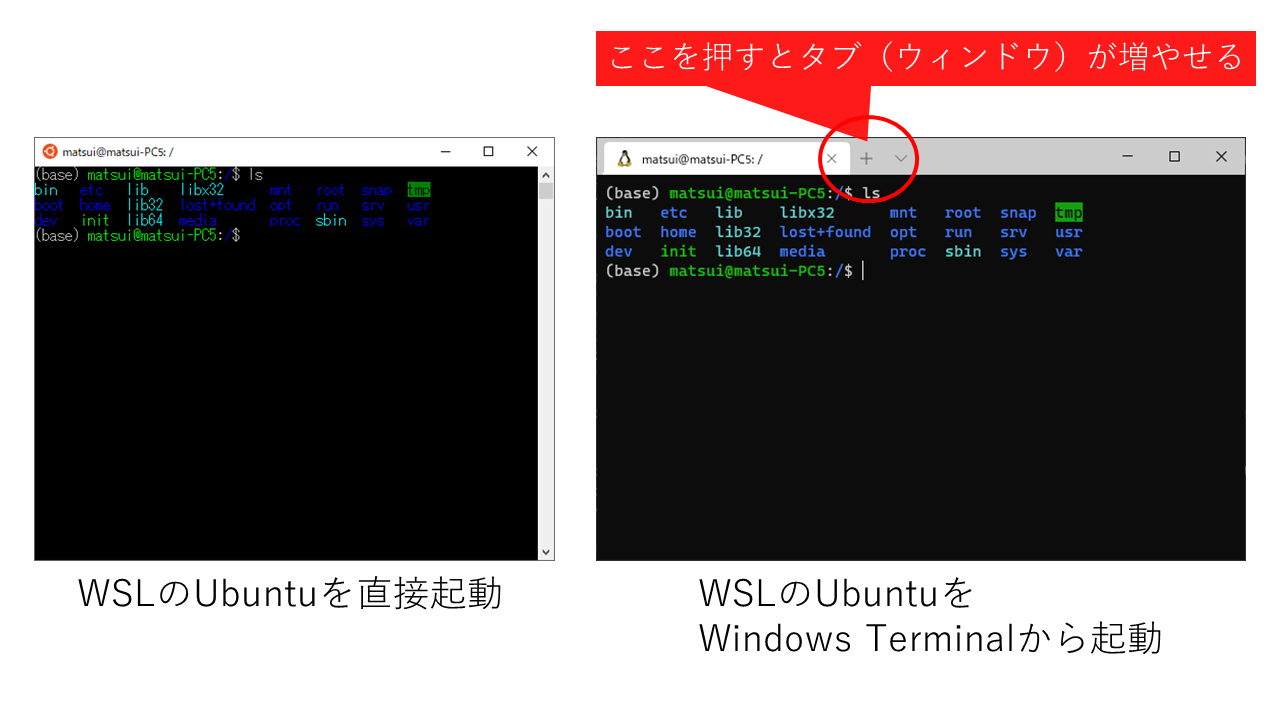
- 同じです。デフォルト設定で比べると、windows terminalのほうが綺麗です。また、windows terminalの場合はタブがついていますので、いくつもウインドウを作れます。
-
\tで整列できるのは後ろの文字列が前の文字列より短い場合だけですか?- 整列はできますが次のブロックに組み込まれます。
と打つと、出力は次のようになります
printf("111\t2\n"); printf("1111111111111\t2\n");111 2 1111111111111 2
- 整列はできますが次のブロックに組み込まれます。
-
GCCとclangの違いはなんですか。なんで2つあるんですか
- clangの方が新しいです。吐くバイナリが違います。よって、プログラムの実行速度が違ったりします。また、c++の新しい機能が入っていたりいなかったりと、様々な違いがあります。 (参考:c++の新しい機能の実装度合い) (参考:GCCとClangの性能比較) 何故2つあるのかについてですが、歴史的には、gccをより良いものにしようとしてclangが作られたようです。 ちなみに、gcc, clang以外にも、様々なc/c++のコンパイラがあります。例えばVisual StudioでC/C++を行うときはMSVCというコンパイラを使います。
-
コンパイルから実行の流れを一度にすることはできませんか?
- できます。
$ gcc main.c && ./a.outのように、&&を使うことでコマンドを連続実行出来ます。
- できます。
-
warningを消すのにはどうしたら良いでしょうか?
- week1のコードを実行すると、以下のようなwarningsが出ると思います。
これは、
main.c:2:1: warning: return type defaults to ‘int’ [-Wimplicit-int] 2 | main(){ | ^~~~main.c中のmain()をint main()にすれば消えます。
- week1のコードを実行すると、以下のようなwarningsが出ると思います。
-
コンパイルするときにa.outなどのファイルを作らず実行だけすることはできるのでしょうか。
- 基本的にできません。
-
c2 = -127とした時、c1 - c2はchar型の表現できる限界を越えているように思うのですがなぜ正確な計算結果が表現されるのでしょうか- 「char型同士の計算」そのものはint型で行われます。結果の値を「変数に代入(保存)する」ときは、charの限界を超えることは出来ません。型変換の章で詳しく述べる予定です。
-
アドレスは16進数14桁で表されているので56bitではないですか?手元で実行しても14桁で表示されているように思います。
- ここは桁数は気にしないでください。前に0が詰められているだけで、表示上の都合です。
-
アドレスは先に宣言した変数ほど大きい番号になっているのですがこれはなぜでしょうか
- week1の課題の範囲内では、repl.it/WSLだと宣言順にアドレスが確保されることを確認したのですが、どうやらマックでは書いた順にメモリを確保しない場合があるようです。これはコンパイラがその方がよい or そうしてもよいと判断したからだと思われます。
-
GitHub/repl.itのアカウントは全世界に公開されてしまうのか?
- アカウント名だけは公開されてしまいます。それ以外の情報は隠せます。なので、一切情報をパブリックにしたくない場合は、捨てアカウントを作ってください。ちなみに、GitHubでアカウント名のみ公開して他を隠している例はこちらになります。また、知らない人から自分のアカウントがどう見えるか確認したいときは、一旦GitHubをログアウトするか、あるいはブラウザのシークレットモードから自分のプロフィールページを見てみるといいです
Week2¶
-
repl.itのeducationチームに所属できません/通知が表示されません/指示と違う画面になります
- ブラウザを全て閉じて、PCを再起動してください(再起動しただけでうまくいったパターンが何件もありました)
- ITC-LMSで提出してrepl.itのアカウントでログインしているか確認してください。GitHubと連携していたりすると、気付かないうちにいくつもrepl.itアカウントが出来ているかもしれないので注意してください。また、gmail連携をしている場合は、複数のgmailでログインしているときにややこしくなるかもしれないです。他のgmailからログアウトするといいかもしれないです。
- repl.itに登録しているメールアドレスをチェックしてください。通知メールが行っていると思います。
- きていなければ、迷惑メールをチェックしてください
- それでもダメであれば、松井まで教えてください。登録アドレスを直接招待します。
- それでも画面がおかしい場合は、何度もリロードしたり行ったり来たりしてください。
-
repl.itで、「fork tmplate」ボタンがないです
- 「start project」を押してください(ボタンの中身の文字が変わったようです)
-
小数と整数の計算で0.5ではなく0.500000が出てしまうのですがこれで良いですか?
- 大丈夫です。printfのデフォの表示桁数がたまたまそうなってるだけです。
-
%を出力したいprintf("%%%d\n", 3)だと%3が出力されるはずです
-
Cでは真理値判定の短絡評価がありますか?
- 短絡評価はあります。
||の左側が真のときは、右側は評価しません。
- 短絡評価はあります。
-
&&と||はどちらが優先されますか?&&が優先です
-
./ a.outでエラー吐かれる./a.outとしてください。スペースは入れないでください。コマンドラインはスペース見てるので、それだと一文字目がコマンド、二文字目が引数だと見られてしまします。
-
文法的には、いかなる場合の空白やインデントは無意味ですか。
- インデントは、基本的に見やすさを整えるものです。全くインデントしなくても、構文的にはOKだと思います。
-
空白について、どのような場合が見やすさのためで、どのような場合は構文の要請なのか、シンプルなルールで答えるのは難しいと思います。例えば、「通常は」演算子の前後の空白は構文の要請ではなく可読性のために入れます。
ですが、次の場合はどうでしょうか?int a = 1, b = 2; int c1 = a + b; // こう書いても int c2=a+b; // こう書いてもOK intc3 = a + b; // これはダメこの例でわかる通り、コーナーケースでは空白のある無しやいれる位置で結果が変わります。つまり、a = 1; b = 2; int c4 = a++ + b; // a=2, b=2, c=3 a = 1; b = 2; int c5 = a + ++b; // a=1, b=3, c=4 a = 1; b = 2; int c6 = a+++b; // a=2, b=2, c=3 (c4と同じ)c5が意図した動作なのに、空白をとることでc6になってしまう、ということがあり得ます。なので、「演算子の前後の空白は可読性のためなので、いつでもつけても外してもいい」とは言えないと思います。上のコードは人工的な例ですが、実際のコーディングでもうっかり間違えが発生する場面もあるかもしれません。普段のコーディングでは、IPAの「コーディング作法」などにのっとって空白を入れるとよいと思います。 -
C言語の内部では、このようにプログラミングの記述をパースする際に字句解析器というものを使います。これは3年生で勉強するチャンスがありますので、その際に深く知ることができると思います。
-
for文の中を
++iと書いているのは何か理由がありますか?何となi++の方が馴染みがあるのですが…- どっちでもいいです。c++ coding standardでは、イテレータなどに対しては前置(
++i)にするほうが良いとありますので、私は癖で全て前置にしています。本講義で扱う、単純なスカラー値ではどちらでもいいです。
- どっちでもいいです。c++ coding standardでは、イテレータなどに対しては前置(
-
if文のようにwhile文の中でのみ変数iを有効にすることは出来るのでしょうか
- 出来ないです
-
For文で式4以降は追加することはないですか?
- ないです。for文は
for(式1; 式2; 式3)で終わりです
- ないです。for文は
-
VScode でエラーを示してくれる波線(電球?が表示されなくなってしまったのですが、 どのように対処すればいいでしょうか。
- 一度全て閉じて開きなおしてみてもらえますか?あるいは、新しいディレクトリを作ってやるとどうなりますか?
-
Switch文でbreakを使わないとどうなりますか?
- 次の行に進みます
-
printfで配列の要素ではなく配列自体を出力することはできますか?
- printfには「配列全部を表示する」という便利機能はないです
-
値渡しのところでの質問なのですが、pythonではどのように振る舞うのでしょうか?
- pythonでは「参照渡し」になり、要素を変更可能になります。
-
配列要素を列挙するとき、
{1,2,3,4,5,6,7,8,9}の代わりに、{1,..,9}みたいな書き方はありますか?- ありません。
-
一次元配列なら
a[5]={0};ですべての要素がゼロになると思いますが、多次元配列でも同じようにできますか?- 出来ます。実は多次元配列は以下のようにカッコをネストさせないでも初期化できます
よって、一次元配列と同じように初期化できます。そのため、
// 普通の書き方 int a1[2][2] = { {1, 2}, {3, 4} }; // カッコはネストさせないでもいい int a2[2][2] = { 1, 2, 3, 4 };int a3[2][2] = {0}とすると、全て0で初期化されます。
- 出来ます。実は多次元配列は以下のようにカッコをネストさせないでも初期化できます
-
三次元配列を二次元と同じように{ , , },{ , , }と書くのはどうやるのですか
- 二次元のときと同様に、ネストして書けます
int a[2][3][4]; a = {{{1, 2, 3, 4}, {5, 6, 7, 8}, {1, 2, 3, 4}}, {{... }}}
- 二次元のときと同様に、ネストして書けます
-
一つのファイルでmain関数は一回しか言えませんか?
- はい、一回だけです
-
配列の長さはどうやって取得できますか?
arrayが配列でTが型とすると、以下で取得できますsizeof(array) / sizeof(T)
-
次のような書き方は出来ないと聞いたことがあるのですが、今やったらできました。何故ですか?
int n=10; a[n];- 仰る通り、もともとCの配列はコンパイル時に大きさが決定されなければいけません。ですが、C99から導入されたVariable-Length Array (VLA)という機能により、コンパイル時に大きさが決まっていない配列も作れるようになりました。このVLAが発動したときにエラーを吐くようにするにはコンパイル時に
-Werror=vlaというオプションをつければよいです。試しに以下のコードを考えましょう。これは、#include <stdio.h> int main() { int n = 3; int a[n]; }gcc main.cではコンパイルできますが、gcc -Werror=vla main.cだと次のようなエラーになりますmain.c:6:3: error: ISO C90 forbids variable length array ‘a’ [-Werror=vla] int a[n]; ^~~
- 仰る通り、もともとCの配列はコンパイル時に大きさが決定されなければいけません。ですが、C99から導入されたVariable-Length Array (VLA)という機能により、コンパイル時に大きさが決まっていない配列も作れるようになりました。このVLAが発動したときにエラーを吐くようにするにはコンパイル時に
-
pythonのように空の配列をつくってそこに値を入れていくことはできますか
- できません
-
関数の引数に配列を入れたり、配列を返してもらったりすることは可能ですか?
- 引数に配列は出来ます。配列を返すことはできません。このあたりはweek3か4かでやります
-
クイズ1のaverage関数についてなのですが、10.0と31.1を引数に渡して平均をとったら20.55ではなく20.549999が出力されてしまったのですが、なぜなんでしょうか?
- 浮動小数は数字を完全に表現できるわけではないので、そういうことが起こります。
-
関数の引数に関数を入れることは可能ですか
- 関数そのものは入れられないのですが、「関数へのポインタ」というものを入れることができます。これはweek4でやるかもしれないしやらないかもしれないです
-
関数から出た値を何処かの変数に書いて、それを入力というのは大丈夫ですか
- 以下のようなことはもちろん大丈夫です。
int a = 10; int b = f(a); int c = f(b);
- 以下のようなことはもちろん大丈夫です。
- 宿題の採点は全部オートなのでしょうか
- 課題によります
Week2の宿題¶
-
課題について質問なのですが、課題にあるコメントは自分で消しても宜しいのでしょうか?
- 消して大丈夫です
-
宿題1は発展課題をやることはやるべきことをやることを包含するので、発展のみやれば良いということでしょうか
- 宿題1は発展のみで大丈夫です。宿題3の発展は別ファイルですのでそちらを編集してください。
-
整数とあるのですが、その通り解釈すれば(負の数も含む)良いのですか(例が2つとも自然数だったので不安になりました)。
- 整数は自然数という理解で大丈夫です(こちら側で検証するときも、いじわるなことはしません)
-
小数の桁数は厳密に指定すべきですか?
- 桁数は厳密でなくてもいいです
-
コードを提出するうえでのコメントは必要でょうか
- 自分のコードの説明のコメントは、あってもなくても大丈夫です。
-
repl.itを使って自分でかいたコードをgithubの課題にコピーするのはダメなのでしょうか?
- replitで書いたコードをgithubにコピペしてください。やり方
-
課題1について、入力が文字列ではなく整数として扱われていますが、整数として扱うのであれば先頭の余計な0は取り除くべきでしょうか(例えば100を逆転した場合、001か 1 のどちらを出力すれば良いですか)
- 100の入力に対しては 1 を出力してください
-
発展課題1でn=2^32-1などの入力は想定したほうが良いでしょうか。
- 今回はそのようなコーナーケースは対象にしないので、対応しなくて大丈夫です。今後、コーナーケースを考慮してほしいときは問題文に書こうと思います。
-
int n = atoi(argv[1]);これは何ですか?- コメントに書いてある通り、それを付けると
./a.out 123のような書き方で「123」というユーザからの入力をプログラムに取り込むことができます。これについてはweek5かどこかで説明しますが、とりあえずはそういうものだと思ってください。
- コメントに書いてある通り、それを付けると
-
課題リポジトリがgithubの自分の領域に追加されていないように見えます
- 実はみなさんのアカウント領域にリポジトリにを追加したわけではなくて、
eeic-software1-2020というオーガニゼーションにみなさん一人一人用のリポジトリを追加して、そこにみなさんが自分のリポジトリにアクセスできるようにした、という形になっています。なので、ここをクリックすると、自分の課題リポが見れるはずです。
- 実はみなさんのアカウント領域にリポジトリにを追加したわけではなくて、
-
課題はコピペするなとありましたが、出典を書けばOKでしょうか
- コピペするなと言ったのは友達がやった宿題を丸パクリしてはダメ、という意味でした。例えば教科書を読んでアルゴリズムを勉強してそれを元にコードを書く、といったことはOKです。その場合出典をコメントで書いてください。また、自分がローカルやrepl.itで書いたコードをgithub宿題リポ上にコピーする行為はもちろんOKです。
Week3¶
-
ダブルクオーテーションで括った物の中身はシングルクオーテーションで括られるような数字の集まり、という認識でいいでしょうか
- そうです。シングルクオーテーションは単一の英数字にしか使えません。それは数字と同じです。以下の通り、'
aa'のように複数文字二は出来ません。また、ダブルクオーテーションの中身が文字集合 + null文字であることは、以下の例からわかると思います。int c1 = 'a'; int c2 = ':'; int c3 = '?'; int c4 = 'aa'; // 通らない// s1とs2は同じ char s1[] = "hello"; char s2[] = {'h', 'e', 'l', 'l', 'o', '\0'};
- そうです。シングルクオーテーションは単一の英数字にしか使えません。それは数字と同じです。以下の通り、'
-
配列を引数とする関数をプロトタイプ宣言する際に、配列の型は何と書けばいいですか
- そのまま書いておけばいいです。例えば
int a[]のときは、のどれでもOKですint hoge(int a[]); int hoge(int *); int hoge(int []); int hoge(int *a);
- そのまま書いておけばいいです。例えば
-
リテラルとは何ですか?
123とか、"abc"とか、値そのもののことです。変数ではなく。int a = 123;は、aという変数に、123というリテラルを代入しています。 リテラルは変更できないです。つまり、「123」そのものは変更できません
-
strcmpの例でなぜ-100になるか教えていただきたいです。
- これは処理系依存。値自体に注目するべきではなく、正か負か0かのみが重要です。今回-100になるのは、おそらく下記のようなものに近い実装になっているからだと思います。すなわち、差異が生じたときの
charの値の差になっていると思いますKing, p306#include <stdio.h> #include <string.h> int mystrcmp(char s[], char t[]) { int i; for(i= 0; s[i] == t[i]; i++) { if (s[i] == '\0') { return 0; } } return s[i] - t[i]; } int main() { char a[] = "abc"; char b[] = "abcd"; printf("%d\n", strcmp(a, b)); // -100 printf("%d\n", mystrcmp(a, b)); // -100 }
- これは処理系依存。値自体に注目するべきではなく、正か負か0かのみが重要です。今回-100になるのは、おそらく下記のようなものに近い実装になっているからだと思います。すなわち、差異が生じたときの
-
宿題の解答などは配布する予定でしょうか?
- 配布する予定です(いつかは未定)
-
先生はvscode使っていますか?もし使っていたらオススメの拡張機能教えて欲しいです!
- 自分はデフォルト厨なのであまり拡張機能を使ってないですが、Remote Developement (Remote SSH, Remote WSL)はよく使います。あまりプログラミングとは関係ないですが、Rainbow CSVは便利だと思いました。
-
「十分に長い配列」は実用的にはどう用意しますか。結合なら文字列の長さを取得して足し算するような形ですか。
- これは難しい質問なので、問題に応じて、ということになってしまいます。任意の長さがほしいときは
mallocという機能を使います。
- これは難しい質問なので、問題に応じて、ということになってしまいます。任意の長さがほしいときは
-
hogeとfugaってよく出てくると思うんですけどなんですか?
- 日本語のプログラミング文化圏で使われるスラングです。メタ構文変数と言うそうです。hoge, fuga, piyo。英語だとfoo, bar, とか
-
sizeof(string)の返り値はsize_tと聞いたのですが、これはunsigned longなのですか?
size_tは何等かの型の別名になっています。その型は環境依存です。64ビットマシンのgccだとunsigned longだと思います。
-
通常の算術型変換のところで、c4は最終的にintですか。
- 以下の部分ですね
上記で、右辺の、
char c1 = 10; char c2 = 100; char c3 = 20; char c4 = c1 * c2 / c3; // 整数拡張。c1もc2もc3もintに変換されるc1 * c2 / c3の計算が行われた結果はintです。これをc4にいれるときにcharになります。
- 以下の部分ですね
-
int同士の場合でintの限界を越える場合はerrorになるのですか?
- 間違った値になります。しかしcompile errorなどは返ってきません。
-
いままでint(変数)と書いていたのですが、(int)変数との違いはありますか?
- C++ならできますがCだとその表記はないです。
-
クイズの「i = c; c = i」は何ですか。
- 以下のような意味でした。
int main(void) { int i; char c = /* 何らかの値 */; i = c; c = i; }
- 以下のような意味でした。
-
エディタでVimとかはいかがですか?今のうちにEmacsに慣れておいたほうがいいでしょうか
- 電気系はemacsなんです。。。。個人的には、3年でミッチリやるので、今無理して慣れなくてもよいのではと思います。3年の実験のときなどに詳しい友達に教えてもらったりしながら学んでいけばいいかもしれません。興味のある方は次の記事が最近のemacs情勢の俯瞰になっておりよいのではと思います:2020年代のEmacs入門 ちなみに、もちろん、vimでもいいです。エディタはなんでもいいです。
-
整数は出来るだけ小さい型になり、少数はいつもdoubleリテラルなのですか
- 以下はC99かつ64bitマシンの場合の説明です。整数リテラルは、intで表現できる場合はintです。intで表現できない場合、long intになります。
King, p129 - 少数はいつもdoubleなのです。(C言語を作った人たちは、doubleに重きを置いていたらしいです)
King, p152
- 以下はC99かつ64bitマシンの場合の説明です。整数リテラルは、intで表現できる場合はintです。intで表現できない場合、long intになります。
-
3.223fのように後ろから型を明示するのもキャストですか?
- ちがいます。これは「float型のリテラルである」という指定です。
3.223fと書いたとき、「float型の変数」が一個発生し、それの値が3.223になります。doubleは一切発生しません。 一方、(float) 3.223と書くと、まず「3.223」という少数リテラルがdoubleとして生成されます。そのあと、それがfloatに変換されます。なので、変換作業が発生しています - ただし、コンパイラは賢いので、もしコンパイラが「最終的に同じになるから必要ない」と判断した場合、(float) 3.223 と書いてもdoubleが発生しないかもしれません。 このようなコンパイラによる最適化は別の話で、他の一般的な部分でも、コンパイラは計算を省略したりすることはあります。
- ちがいます。これは「float型のリテラルである」という指定です。
-
前のやってみようなんですけど、strcatをする際に十分な長さを確保しなかったにも関わらず、strcatが成功したんですが、何故でしょうか?正確には、s3[6]でhogeとし、fugaを結合したら、sizeof(s3)が6になり、strlen(s3)が8になりました
- これは偶然うまくいっているように見えているだけです。strlenは配列の境界を超えてその外側まで
'\0'を探しにいっているので、非常に危険な状態になってます。
- これは偶然うまくいっているように見えているだけです。strlenは配列の境界を超えてその外側まで
-
Cで文字列リテラルに日本語が入ったらchar[]にどう渡されていますか?
- 日本語は8bitではなくもっとバイトを使って表現されます。
-
コードを書くとき今のうちから計算量などを考えながら書いた方が良いでしょうか?
- 計算量を知っているなら意識すればいいと思います。まだ習っていないと思うので、本講義の範囲ではそれが重要になることは少ないと思います。3年のアルゴリズムの講義でガッツリ習います
-
strcpy でsizeof(s2) がstrlenより大きくなる理由を聞き逃してしまったので教えていただけないでしょうか?
- sizeofは配列の長さです。strlenは、
'\0'が出るところまでの長さ、すなわち文字の個数です。
- sizeofは配列の長さです。strlenは、
-
文字列をコピーする際に、コピー先に既に別の文字列が入っているときはどうなりますか?
- 上書きされます。以下が例です。
// 挙動の確認のためにちょっと長めの配列を作る char a[6] = "abcd"; // {'a', 'b', 'c', 'd', '\0', '\0'} char b[6] = "xx"; // {'x', 'x', '\0', '\0', '\0', '\0'} strcpy(a, b); // bの内容をaにコピー。正確には、 // 「bの配列の先頭から`\0`が発生するまでの間のcharたち、この場合では{'x', 'x', '\0'}」を、 // 「aの先頭から順番に埋めていく」という処理。aの最初のほうは上書きされる。 // また、aのあまりの部分はケアしない printf("%s\n", a); // xx // 今、実際のaの中身は以下のようになっており、最初の'd'が残っている。 // cではこれは完全にOK。文字列配列では、最初に`\0`が出たところまでがvalidな文字列で、 // その後ろには何が入っていてもいい。 // a: {'x', 'x', '\0', 'd', '\0', '\0'} // 確認 for(int i = 0; i < 6; ++i) { printf("%c, ", a[i]); // x, x, , d, , , } printf("\n");
- 上書きされます。以下が例です。
-
putcharの出力はintなのになぜ文字が表示されますか
- 文字は実はただの小さい整数なので、intでもcharでもよいです
-
エンターを押すと終了する場合とctrl+Dでないと終了しない場合の違いをもう一度教えていただいても良いですか。
- エンターは
'\n'を送っていて、ctrl + D はEOFなので違うものを送っています。
- エンターは
-
複写スラッシュプログラムはprintfがないのに文字を出力していますが、これはa.outとcatコマンドを同時に処理しているということですか?
- catはコマンドであり、それを行っているわけではありません。printfもpucharも出力関数ですが、putcharのほうがより低次な処理です。
-
以下で、5行目のc = getchar();がなんのためにあるかがわかりません...
int main() { int c = getchar(); // 一文字読み込む while (c != EOF) { // 最後でなければ putchar(c); // 一文字書き込む c = getchar(); } }- 5行目がないと、次の語をとってこれません。これにより、
cは常に最初の一字となります。よって、whileの内容は常に真になります。結果として、whileの無限ループになってしまい、最初の一字が吐き出され続けます。
- 5行目がないと、次の語をとってこれません。これにより、
-
Cは場合によって文字の配列を表したりその要素を表したりするのでしょうか、頭こんがらがってるんで質問がおかしかったらすみません
- intやcharのときは、全て単に整数の配列です。printfとかをするときに、小さい整数の場合は、文字として表示することができるだけです
-
.datは何の拡張子なのでしょうか
- 適当です。.txtでもいいです
-
getcharにより入力した値(文字?)をバッファとして溜め込んでいるというのは、変数cのアドレスに保存されるというイメージでしょうか?それとも別の場所に保存されて、その後エンターを押すと出力されるようになっているのでしょうか?またはそもそも保存などしていないのでしょうか?溜め込んでいるという表現が具体的に分からないのでその点について詳しく教えていただきたいです。
- ここでのため込みは、これまでのC言語の話とは関係のない、別の領域です。cのアドレスではないです。
-
小文字を大文字に変えるプログラムと複写プログラムを組み合わせるやってみように関してなのですが、小文字プログラムのlowerのifの条件を‘a’<=c<=‘z’とすると文字化けが発生したのですが‘a’<=c&&c<=‘z’とするとできました。この二つに違いはあるのですか?
- Cでは a < b < c のような表記はダメです。演算子の説明のクイズのところを参照にしてください。
-
複写プログラムで、改行のたびに出力がされるのはなぜですか
- エンターをうつまでは入力がバッファという領域にためられて、エンターを押した瞬間にそれらがgetcharに流れこむからです。
-
putcharとprintfの違いは何なのでしょうか?何故二つあるのでしょうか?
- そもそもなぜ二つあるのかはわからないですが、putcharのほうが低次の処理で、printfは高機能便利関数です。ほかにもputcとかputsとかたくさんあります
-
バッファに貯めずに、リアルタイムで入力を得るような方法もありますか?
- getcharを使う限りは、どうやら簡単な方法はないようです
-
入出力の「入力される文字をカウントする関数」のところで、ターミナルで実行すると、
のように最後に大文字のDが表示されてしまうのですが、なぜでしょうか?VScodeを使っています。試しにrepl.itでもやってみたら、そちらでは5だけが表示され、うまくいきました。$ gcc main.c && ./a.out abcd 5D- ターミナルの設定のような気がします。MacでVSCodeでやると同じように5Dとなるようです。他には、./a.out実行中にrepl.itではctrl + Cを押しても何も出てきませんが、MacのVSCode(というかlocalのterminal)だと
^Cと表示されるのと同じだと思います。ちなみに^Dは入力であってそれが一緒に表示されているだけなので、出力は正しく5になっています。
- ターミナルの設定のような気がします。MacでVSCodeでやると同じように5Dとなるようです。他には、./a.out実行中にrepl.itではctrl + Cを押しても何も出てきませんが、MacのVSCode(というかlocalのterminal)だと
Week3の宿題¶
-
自分の課題のリポジトリにgitignoreなどのファイルをpushしても良いでしょうか?
- okです
-
細かいのですが、READMEでの想定出力でpoint 1などなっている場所がありますが、正しくはpoint: 1 だと思われます。
- タイポです。すいません。。。
point: 1でお願いします。二日目以降に宿題リンクをダウンロードした方は、既に修正されています。
- タイポです。すいません。。。
-
先ほどたまたまGithub Classroomのトップページ( https://classroom.github.com/ )に移動したところ、追加の権限を求められましたが、こちらについてはauthorizeしなくてもよいでしょうか。
- これは宿題をやる側(学生側)の権限移譲ではなくて、classroomの運営をする戦線側の権限移譲のような気がします(たぶんこれをやると、自分でclassroomを作れるようになるきがします) authorizeしないでも宿題が出来ているなら、とくになにもしなくていいと思います
-
宿題1で手始めにファーストネームの1文字目を大文字で出力するプログラムを書こうと思ったのですが、コンパイルできるのにもかかわらず実行するとSegmentation fault と出てきてしまうのですが、これはどうすれば出なくなるのでしょうか…?
- 宿題1ではargvで入力データを受け取ります。getcharと混ぜないでおいてください。
-
蛇のゲームの挙動について、自分自身に突っ込むような動きのときどうするか?
-
禁止するとうパターンと、折り返すというパターンがあると思います。今回はどっちでもいいです。 例:
kkkkmmmjjjjk以下、わかりやすさのため先頭を大文字の「O」にしています -
禁止するパターン:自分の体を障害物とみなして、動けなくする(オリジナルの蛇のゲームはたぶんこっちです)
----- ---x- -x--- Ooo-- x-1x- - 折り返すパターン:自分のしっぽは頭と重なっている
----- ---x- -x--- oO--- x-1x-
-
-
発展課題で、ヘビの頭をo以外の文字で表したいのですが、採点上問題がありますか?
- 課題2Eは自動採点にするつもりなので、頭は「o」にしてください。課題2Fはなんでもいいです
-
課題2について確認なのですが、最終的に表示するのは過程を省いた最後の盤面だけで良いですか?例えば、kkk+Enterと打ったとき、表示されるのが右に三回移動したもののみだけでいいのか、右に一つ移動したものを三つ表示するかということです。
- 右に三回移動したもののみでOKです
-
自由課題のファイル名に関して、README.mdでは main_2_5.c と書いてありますが、main2_5.c ではないですか?
- タイポですすいません。。。main2_5.c でお願いします(アンダースコアは1つだけ)
Week4¶
-
ポインタのメモリが64ビットになる理由がいまいちわからなかったのでもう一度説明お願いします。
- ポインタの値は、アドレスを表現する必要があります。アドレスは、64ビットマシンの場合、64ビットの整数で表現されます。なので、ポインタは64ビット環境では64ビット整数になります。
-
代入の際に、
p=&aではなく*p=aとはできないですか?- できないです。なぜなら、代入するまえは、まだ
pがどこを指すか決まっていません。その状態で*pをすると、どこも指していないので、エラーになります。図1を見てじっくり考えてみてください
- できないです。なぜなら、代入するまえは、まだ
-
*pはaの別名くらいの解釈であってますか?
- OKです(ちゃんとpにaをセットした後なら。)
-
例えば、
をint a = 10; int *p = &a; printf("%p = %d\n", p, *p);printf("%p = %d\n", &*p, *&*p);みたいに書いてもよいですか?- そのprint結果は同じになります。ただし、
pと&*pは違うもの(前者はポインタ「変数」、後者は「aのアドレス」)ので注意してください。クイズ参照。
- そのprint結果は同じになります。ただし、
-
pがa、qがbを指す時、p = qとしたあとに、*p = cとすると、*qもcになるのは、p = qとした時点で、どちらもbを指し、*p = cはbをcに変更したことになるから、bを指していたqもcを指すという理解で合ってますか?- その通りです!
-
(*p)++ではなく*p++と書くとどのように処理されるのでしょうか?*p++は*(p++)と等価なので、ポイントpのさす先が一つ増えた先にいってから、参照しますね。(気になるのでみにきていたソフ2の斎藤先生より!)
-
i++と++iは返り値が違った気がするのですが、++*p;と(*p)++;は同じものとして扱っていいのですか?- 違います。まさに、
i++と++iは返り値が違ったのと同様に、それら二つも返り値が違います
- 違います。まさに、
-
printfの中で
%dとしてもwarningが出るだけでポインタの表示ができたのですが、危険ですか?printf("*&a: %d, , *&p: %d, &*p: %d", *&a, *&p, &*p);- 危険ですのでやめましょう。以下が例です。
#include <stdio.h> int main() { int a = 10; int *p = &a; // 0x7ffe570988dc : 正しい。p表記でポインタとして表示。親切にも0xをつけてくれる printf("%p\n", p); // 7ffe570988dc : 値としては正しい。pを直接8バイトの整数として扱い、16進数として表示 // 値が上と一致することに注目。ですが危険なのでやめましょう printf("%lx\n", p); // 140730358663388 : 値としては正しい。pを直接8バイトの整数として扱い、10進数として表示 // ですが危険なのでやめましょう printf("%ld\n", p); // 570988dc : 正しくない。8バイト整数の下部4バイト分だけを16進数で表示 printf("%x\n", p); // 1460242652 : 正しくない。8バイト整数の下部4バイト分だけを10進数で表示 printf("%d\n", p); }
- 危険ですのでやめましょう。以下が例です。
-
クイズでf1,f2の結果がnilになったのですが、nilはポイント先が存在しないということですか。
- そうです。
-
f1()はポインタ変数aがローカルに別の値に変わっているだけで、ローカル変数のアドレスを返す例にはなっていない気がします…
- 本当ですね。。。。。これは出題のミスでした。ページを更新しておきました。
-
クイズで
*min = a[0]をmin=aにするとうまくいきませんでした。なぜですかaとだけ書くと、これは「配列aの先頭要素のアドレス」を意味します。なので、min = aという書き方は、minがaの配列を指すようになってしまいます。ここでは、minは配列ではなく単体のintを指すべきなコードになっています
-
関数において、returnをしないときで数値計算するときは基本ポインタを使うという理解でよいですか?
- そうとは限らないと思われます。ポインタを使わずとも情報を返す方法として、「グローバル変数をいじる」「static変数を扱う」「ファイルに書き出しを行う」などがあり得ます。また、「printだけを行う」などの場合もあります。
-
クイズで、関数の中身がこれでダメなのはなんでですか?
aを二回使うのはダメです。int a = a[0]; int b = a[0]; for (int i = 1; i<n;++i){ if (a[i]>a){ a = a[i]; }else if (a[i]<b){ b = a[i]; } } *max = a; *min = b; -
すみません、テストかレポートの日程ってすでに決まっていますか?
- レポートの予定です。レポートの日程は決めてないですが、最終週の後とかにすると思います(まだ未定)
-
今回はintなので++pでいいけれど、doubleとかなら+する値を変えなければいけないということですか?
- ポインタを1個進める場合は、doubleでも++pです。 ちなみに、ポインタ関係なく、doubleの変数にも++はできて、1.0を足すという動作になります
-
#defineしたときの型は何になりますか?#define N 5のように、intにおさまる整数のときは、intになります。ここは、コンパイルする前に、「N」というテキストをすべて「5」で書き換えています。なので、本来そこにint a[5]と書いたときと全く同じ動作になります。なので、intに収まる整数の場合は、intになります
-
#defineするのと、グローバル変数の違いは何でしょうか。- これは全然違います。defineはコンパイルの前に全体を置換するような操作です。グローバル変数は、変数を生成する作業です。例えば、defineで決めたものに値を代入する(
#define N 5としたあとにN = 3)などは出来ません。グローバル変数は、後で代入することができます。
- これは全然違います。defineはコンパイルの前に全体を置換するような操作です。グローバル変数は、変数を生成する作業です。例えば、defineで決めたものに値を代入する(
-
nil とNULLがどう違うのかよくわかりません
- nilは、NULLを
%pで表示したときに表示されるものというだけです。自分で書くことはありません。自分で書くときは全てNULLです
- nilは、NULLを
-
constと#defineの違いはなんですか?cont int a = 3;と#define a 3の違いということですよね。const はあくまで変数を作って、それをアクセス不可能にしているだけです。defineは、繰り返しですが、ソースコードの文字列を置換するものです。なので、違います。差異の例として、以下に(1) アドレスの有無、(2) スコープ内外の挙動を示します。#include <stdio.h> #define A 3 const int B = 3; int main() { //printf("%p\n", &A); // これはエラー。整数リテラルなので、アドレスは無い printf("%p\n", &B); // これはOK。あくまで変数なので、アドレスがある。 if (1) { #define A 5 // この書き方はdefineを二度していておかしいと警告が出る printf("A: %d\n", A); // 5 値は更新される } printf("A: %d\n", A); // 5 のまま if (1) { const int B = 5; // この書き方は合法。新しいスコープ内で別の変数として定義 printf("B: %d\n", B); // 5 値は更新されている } // このスコープを抜けたときに、上書きされたBは消える printf("B: %d\n", B); // 3 元のグローバルのBに戻る }
-
グローバル変数は使うなと教わった気がするのですが、
#defineは使っても良いのでしょうか。また、#defineを使うことのデメリットはなんですか。- 定数を定義するときに、グローバルのconst変数を使うのか、defineを使うのか、どちらがいいのか?という質問だと思います。
King, p467曰く、絶対的なルールはないそうです。しかし、数や文字列を表現するときはdefineをおすすめとのことです。というのも、defineならばOKですが、グローバルconst変数ではダメな例があるからだそうです。その一つの例として、switchではdefineしか使えないそうです#include <stdio.h> // defineならOK #define N 10 // これをconstグローバル変数にすると、コンパイル出来ない //const int N = 10; int main() { int a = 10; switch (a) { case N: printf("Ten!\n"); } } - defineを使うデメリットとしては、使いすぎると予期せぬ挙動になる点だと思います。実はdefineには定数だけではなくマクロという関数のようなものを作る使い方もあり多機能なのですが、それらを使いすぎると想定とは違う挙動になりえます。なので、使い過ぎに注意です。基本は、簡単で自明な定数だけにすればいいと思います。
- 定数を定義するときに、グローバルのconst変数を使うのか、defineを使うのか、どちらがいいのか?という質問だと思います。
-
aと&a[0]は同じ値のポインタなのに、sizeof(a)=20、sizeof(&a[0])=8となるのはなぜですか?sizeof(X)は「Xのメモリ消費量」を返します。より正確に言うと、「Xの型のメモリ消費量」です。Xの値は関係ありません。なので、sizeof(a)では、aは「intが5個の配列という型」なので、20バイトを消費します。sizeof(&a[0])では、&a[0]は「intへのポインタ」なので、8バイトを消費します。 講義中での答えは不正確だったので、答えを更新しました
-
先週の課題2で何もいじってない状態でk連打していて思ったのですが、配列のオフセットの指定を適当にうちまくってると予期せずシステム使用領域をいじって落ちるみたいなことは起きうるのでしょうか?それともそこは保護されていますか?
- セグメンテーションフォルトというエラーになりえると思います。その場合、落ちます。
-
aが配列のとき、sizeofの値が違うのに、a == &a[0]の結果は真になるのが不思議ですaと&a[0]はsizeofの結果は違いますが、どちらも値としては同じアドレスを指しているので、真になります(%pで表示すると同じです)。これは普通の変数で型はintとcharで違うけど値が同じ場合でも同様ですint a = 3; char b = 3; if (a == b) { printf("%ld %ld\n", sizeof(a), sizeof(b)); // 4 1 }
-
配列やそのポインタを扱う際のaとa[]の使い分けについてもう一度詳しく教えてください。
- ポインタと配列 の図をよくながめてください
-
教材の中の
void set_one関数内でのa[i]のaというのはポインタで、その際にa[i]という表記が許されるのは、ポインタに対して添字表記が許されているから、という解釈であっていますか?既出でしたらすみません。- その通りです。
-
int型の配列aについて、
printf(“%p, %p, %p\n”, a, a+1,a+2);というのを誤ってprintf(“%p, %p, %p\n”, &a,&a+1,&a+2);としてコンパイルしたら12ビット差になったのですが、何か意味がありますか?- これは難しく、week5で説明するかどうかまだ決めていないですが、
aと&aは%pしたときの値は同じですが、型が違うため、そのようなことが起こっています。例えば、int a[] = {1, 2, 3};とします。aの型は、配列なので、int *と考えることができます。よって、1を足すということは、sizeof(int) * 1で4です。一方で、&aの型は、実はint (*)[3]というものになっています。これは、「int型3つ分に対する配列」を一つの単位とするポインタです。なので、これに1を足すということは、sizeof(int) * 3 * 1ということで、12になります。
- これは難しく、week5で説明するかどうかまだ決めていないですが、
-
void set_one(int a[], int n)のところでa[]をaと書くとエラーがでてしまうのはどうしてでしょうか?またポインタのa+2をa[]+2と書くのはダメなのでしょうか?void set_ont(int a, int n) { ... }これだとaはint一個という意味になってしまいます。また、a[ ] + 2のような表記は許されてないです
-
strlen1関数の引数に配列sを代入しても同じですか
- OKです。
int strlen1(char s[]) {...}にしてもOKです。
- OKです。
-
const char *sのようにconst付きのポインタで変数を受け取ったときに、char *p = s;のようにコンスト無しのポインタに変換するとsは変更可能になってしまうのでしょうか。もしそうなら、const char *sと宣言したのになぜ変更可能になるのですか。- 変更可能になってしまうようです。警告が出るだけのようです。
K&R p269曰く、const int *pci; 'pciの型は"const int"へのポインタであり,pci自体は他の場所を指すように変更できるが,それが指す値はpciを通した代入で変えることはできないとあります。「pciを通した代入」では変えることはできないですが、pciを通さない代入では変えることができるようです。
- 変更可能になってしまうようです。警告が出るだけのようです。
-
strlen3の例で、
const char *sとあるのに、whileの中で「s++;」によってsが変更されているように思えてしまうのですが、どういうことなのでしょうか。*sの変更はできません。sの変更(++sとか)はOKです
-
プロトタイプ宣言にconstは必要ですか?
- いります
-
先週の課題についてです。main2_4.c以降を作ったのですが、contributorのところに先生のウサギのアイコンがいないのですが、これは大丈夫なのでしょうか(作ったことは先生の方で認識されているのでしょうか)。
main2_4.cは自分でファイルを作る課題だったので、松井はコントリビュータではないです 授業中に答えたときは松井も勘違いしていました
-
最大値を求めるクイズで配列aの最大値をmaxの指すところに入れるのではなく配列aの最大値の入っているアドレスをmaxに代入してはいけないのはなぜですか
int *maxというのは、(1) 関数内で 8バイトのポインタ確保して、それにmaxと名付ける。(2) そのポインタの値は、呼び出し元のmax_valのアドレス という状態です。そして、max_valのアドレスを経由して、元のmax_valを編集します。 なので、「a中の最大値のアドレス」をmaxに代入すると、関数内のローカル変数であるmaxになんらかのアドレスがセットされ、その段階でもとのmax_valはもう一切関係なくなります。関数が終わると、maxも終わり、何も残りません
-
すべてアドレス参照の言語(pythonとかですか?)に比べてポインタの存在ってどのような利点があるのでしょうか
- ポインタはローレベルな処理なので、やっていることがメモリレイアウトレベルで全て明らかになるのが良いところです。速度やメモリ効率もよく作れます。逆にCやC++側からすると、pythonはどのようにデータを受けわたししているかわからないので、気持ち悪かったりします。
-
文字列を関数に渡す際、プロトタイプ宣言でvoid f(char[]);という書き方を見ましたが、これはvoid f(char s[]);の略形だと考えていいでしょうか。
- そうです。
-
「a中の最大値のアドレス」をmaxに代入してうまくいくコードを見せていただくことはできますか。
- この問題は良い問題だと思ったので、week 5で詳細に説明します
-
ポインタの定義をmain()内で行わないと、エラーが出るのはどういう理由からなのでしょうか。具体的には
とすると#include <stdio.h> int a = 10, b = 3; int *p; int *q; p = &a; q = &b; int main(){ printf("a: %d, b: %d, *p: %d, *q: %d\n", a, b, *p, *q); p = q; printf("a: %d, b: %d, *p: %d, *q: %d\n", a, b, *p, *q); }とエラー文が出、(定義で不具合がある?) a, b, p, qの定義もすべてmain内で行うと、不具合が全くない、というものなのですが… clang-7 -pthread -lm -o main main.c main.c:6:1: warning: type specifier missing, defaults to 'int' [-Wimplicit-int] p = &a; ^ main.c:6:1: error: redefinition of 'p' with a different type: 'int' vs 'int *' main.c:4:6: note: previous definition is here int *p; ^ main.c:7:1: warning: type specifier missing, defaults to 'int' [-Wimplicit-int] q = &b; ^ main.c:7:1: error: redefinition of 'q' with a different type: 'int' vs 'int *' main.c:5:6: note: previous definition is here int *q; ^ 2 warnings and 2 errors generated. compiler exit status 1- mainの外では、変数初期化以外の代入はできないです。これはポインタと関係ない問題です(pythonでは出来ます)
Week4の宿題¶
-
week4の宿題3の「
include <string.h>してはいけませんが、必要に応じて、授業で扱った文字列操作関数を自由にコピーして使ってもいいです。」という文がありますが、これはどういう意味でしょうか?#include <string.h>すると、cが準備している strlen 関数などを使えます。それは使わないようにしてください。そうではなく、授業中には例えば strlen1 関数は実際に作りましたよね。そういうのはコピーして使っていいです(全部調べてないですが、string.hをインクルードすると、問題をすごく簡単に解けるような便利関数とかがあるかもしれないです。今回の課題の目的は、ローレベルにchar配列を直接いじってもらいたいので、そういう便利関数は使わないようにしてください、という趣旨です。strlenとかは授業でchar配列をいじるレベルで勉強したので、使っていいです)
-
宿題3、文字置換アルゴリズムについての質問です。マッチする文字列に重複がある場合、例えば
である時に、その出力がs[]="abbbccdbbbbb" old[]="bb" new[]="xxxもしくはs[]="axxxbccdxxxxxxb"もしくはs[]="axxxccdxxx"と置換することを考えることができると思うのですが、どの置換方法がよろしいでしょうか。s[]="axxxxxxccdxxxxxxxxxxxx"s[]="axxxbccdxxxxxxb"でお願いします。
Week5¶
-
先週分の課題で締め切りが過ぎたと思うのでとりあえず提出したもののエラーの原因などを知りたいんですが、どこに質問するのがいいでしょうか?
- まず、答えを近日中に配布します。また、なぜおかしいか知りたいときはslackに載せてくれると松井かTAが答えます。もしこっそり聞きたければissueできいてください(ただし、もしすごいたくさんの人からissueが来た場合は、返事が遅れます)
-
課題でエラーが出てるかどうかはどのように確認できますでしょうか
- とりあえず「想定入力・出力」の部分がクリアできていればOKです
-
クイズの一個目の意味があまりわからないんですけど、このvoidに対してこのintを書くとはどう言う意味ですか
- 一個目は、main側で
int ansを作って、find_largest(arr, 3, &ans)というふうにそのアドレスを渡す、という形式です。ここで、そうではなく、直接答えをreturnする次のような形式の関数を作ってください、という意味です:int ans = find_largest_(arr, 3);
- 一個目は、main側で
-
ポインタのポインタのポインタは作れますか。
- 作れます。宿題で扱おうかどうしようか考えているところです(結局やりませんでした)
-
ポインタのポインタ変数の生成をする
**は、ポインタを生成する*とは別の概念ですか。- 同じです。
intに対するポインタの宣言はint *でした。つまり、「対象の型」 + 「*」です。なので、double *に対するポインタの宣言は(double *) *なので、double **です
- 同じです。
-
以下の二行で_がついているのとついてないのはどういう違いですか
find_largest2(arr, 3, &p_ans1); p_ans2 = find_largest2_(arr, 3);- 同じ名前だと紛らわしいので、名前を変えただけです
-
ウェブサイトの上の例で、
***p_max=1とかってやればa[?]を操作できるのですか- アスタリスク二個でいいです。
printf("p_max: %p\n", p_max); printf("*p_max: %p\n", *p_max); printf("**p_max: %d\n", **p_max); printf("(*p_max)[0]: %d\n", (*p_max)[0]);普通の使い方をする上では、アスタリスクの個数は基本的に増えないはずです。つまり、ポインタのポインタのとき(アスタリスク2個。p_max: 0x7ffff2b963c0 *p_max: 0x7ffff2b963cc **p_max: 3 (*p_max)[0]: 3int **p)は、***p(アスタリスク3個)とうい表記はしないと思います
- アスタリスク二個でいいです。
-
アスタリスクについては、前回学んだ原理が一貫しているんですね。
- その通りです。基本原理が一貫しているので、それに従えばOKです
-
以下
を、char *hokuriku1[3];とするとどうなりますか?char *hokuriku1; hokuriku1[3];- これはダメです。別のものになってしまいます。
char *hokuriku1;と書いた時点で、hokuriku1は「char型へのポインタ」になってしまいます。メモリ的には、ポインタ一個分しか確保されません。そのあとにhokuriku1[3]とアクセスすると、確保していないメモリ領域にアクセスすることになってしまいます。
- これはダメです。別のものになってしまいます。
-
sizeof(ポインタ) を出力すると8になるのですが、ポインタのサイズは8バイトということでしょうか?
- そうです。64ビットマシンでは、アドレス空間は64ビット整数(=8バイト)で表現されます。なので、それを表現するために、ポインタの大きさは8バイトです Q&A の week4の最初の回答も参考
-
hokuriku1[1] + 1とすると、s2[1]のアドレスをさすということで正しいでしょうか?- そうです
printf(“%p\n”, hokuriku1[1]); // 0x7ffff482895f printf(“%p\n”, hokuriku1[1] + 1); // 0x7ffff4828960 printf(“%c\n”, *(hokuriku1[1] + 1)); // s <- ishikawaのs
- そうです
-
ポインタと配列がごっちゃになってる気がするのですが、
hokuriku1[i][0]と*(hokuriku1+i)は同じですか?- 違います:
int i = 1; printf("%c\n", hokuriku1[i][0]); // 'i' printf("%c\n", *(hokuriku1 + i)[0]); // 'i' // 上の二つは同じです。a[i]と*(a + i) が指すものは同じ、ということです printf("%p\n", *(hokuriku1 + i)); // これは、配列のアドレスになってしまいます。 printf("%p\n", hokuriku1[i]); // 上と同じなのはこれです。*(a + i)とa[i]の変換を適用しただけです
- 違います:
-
ポインタの配列を二次元配列と考えるのは間違っていますか
- 違います。4限で説明します
-
以下のようにすると、a, ba, cba, となる理由を教えてもらえませんか?
int main(){ char c1 = 'a', c2 = 'b', c3 = 'c'; char *alphabets[] = {&c1, &c2, &c3}; char **p; p = alphabets; for (int i = 0; i < 3; ++i) { printf("%s, ", p[i]); // a, b, c } printf("\n"); }p[i]は文字列ではなく文字単体です(最後にnull文字がない) なので、%sで表示できません。
-
クイズの最後の一つ目の解答で
char *animal = "dog";となっている部分の意味がわかりません。ポインタ変数のanimalにdogが格納されているのでしょうか?animalには0x…みたいなアドレスが格納されると思ってしまい、イメージがつきにくいのですが、、- 疑問は最もです。このようにcharポインタを文字列リテラルで初期化するときは特別に、どこかに
"dog"という文字列が確保され、そこを指すようになります。week4の最後を参照してください
- 疑問は最もです。このようにcharポインタを文字列リテラルで初期化するときは特別に、どこかに
-
print_each関数の3行目の
prefectures[i]の前に*を入れないのはなぜですか(prefecuresの要素はポインタだと思いますが)- 文字列
char str[] = "hoge"としたときに、これをプリントするときはprintf("%s\n", str)としたことを思い出しましょう。ここで、strは、配列の先頭アドレスですね。なので、%sに入れるのは、アドレス(とかポインタ)です。なので、prefectures[i]はアドレスなので、OKなのです。
- 文字列
-
Prefectureにkenをつけるコードで、printf中の
prefecture[i]だと配列の最初の文字しかprintfされない気がしたのですが、どうして配列全体を表示できるのですか。printfでは配列全部を一度にprintfはできないとのことだったと思うのですが。%sは文字列全体(配列全体)を表示出来たことを思い出しましょう。それを行っているだけです。
-
int *a[] = {{0,1}, {2, 3, 4}, {5}};ができない理由がよくわかりません。{0,1}というような配列のメモリをどこか適当に準備し、それらの配列の先頭アドレスをaに配列として格納することができそうな気がしてしまいます。- 「int配列をどこかに適当に準備する」とういのは、Cでは許されていない行為なのです。文字列リテラルだけが、特別に許されているのです。ちなみに、自分でどこかに準備するときはmallocという機能を使います。Cでは、malloc相当のことをコンパイラが勝手にやってくれることは無いです
-
int *v[]のクイズでに出てくる**pでp[1][1]と*(*(p+1)+1)は同じということで間違いないですか?- 一緒です。
p[i]と*(p + i)は同じものを指すというルールを二回適用すれば同じになりますね。
- 一緒です。
-
最近っていうのはどのぐらいの年月の話ですか?また、c99というものの機能は積極的に使っても大丈夫でしょうか。後方互換性を意識する必要はありますか?
- C99は2020現在、もう常に仮定して大丈夫だと思います。最近っていうのはいつぐらいかというのは答えづらいですね。。。分野の慣習や情勢によるとしか言えない形です。他の言語の例ですが、c++11(2011に作られたc++の新しいバージョン)は、それ以前と比べてかなり新機能が入りました。そして、最近ようやく「常に仮定」していい状態になってきた、という感じです。5年前はc++11を常に仮定するのはちょっとはばかられたかもしれません(c++11を使える人がまだ少なかったかもしれないし、c++11をサポートしない古いバージョンのコンパイラを使っている人がまだ結構いると仮定できた)
-
arrを単なる1次元配列とみなして、arr[0][0]のアドレスをsとすると、s+1はarr[0][1]のアドレスになると思うのですが、arrを二次元配列として二次元配列のポインタをpとしたときp+1はarr[1][0]のアドレスが出てくると思うのですが、pを使ってarr[0][1]のアドレスを表現できないか、ということです
- 講義中での解答が間違っていました
- 出来ます。この場合のpはarrと同じように扱えるので、単純に以下のように出来ます
int arr[][3] = {{1, 2, 3}, {4, 5, 6}}; int (*p)[3] = arr; // pはarrを二次元配列として指すポインタ。 printf("address of arr[0][1]: %p\n", &arr[0][1]); // 0x7ffe580355d4 // pはarrと同じようにふるまうので、次のように出来る printf("val of arr[0][1]: %d\n", p[0][1]); // 2 printf("address of arr[0][1]: %p\n", &p[0][1]); // 0x7ffe580355d4
-
たまにreplitでなにも実行していないのに永遠にエラーメッセージが流れることがあるんですけど、そういうときはどの様にしたらいいんでしょうか?
- repl.itは機嫌悪いときは悪いので、切ったりつけたりしてみてください。。。
-
最後の一次元配列で考えるものについて、&arr[0][0]とarr[0]が同じアドレスを示すことはわかったんですが、arrも同じアドレスを示すと思ってやってみたところ、アドレスは同じだったんですが関数の引数としては使えませんでした。違いは何ですか?
- 値はアドレスで同じですが、型が実は違います。ポインタの例で出したとおり、「arr」は型としては
int[2][3](二重配列)であり、それをポインタで指すときは(int *)[3]になるのです。 詳しくはチートシートをどうぞ
- 値はアドレスで同じですが、型が実は違います。ポインタの例で出したとおり、「arr」は型としては
-
2次元配列arrのポインタで、
arr[1][1]の値にアクセスするには、(*(p+1))[1]とすればよいでしょうか?- そうです。
p[1][1]でもいいです
- そうです。
-
arr[0]と&arr[0][0]も型が違いますか?- ここ、講義のときにあやふやだったので、詳細に調べてきました
- 違います。
int arr[][3] = {{1, 2, 3}, {4, 5, 6}};とするとarr[0]の型はint [3](要素3つの配列)です。sizeof(arr[0])は12です(配列なので、要素分のバイトの合計)&arr[0][0]の型はint *(intに対するポインタ)です。sizeof(&arr[0][0])は8です(ポインタなので)
- ただし、注意として、
arr[0]は普通のint配列なので、関数に渡すときはint *で渡します。なので、上記は二つとも、関数に渡すときは同じように渡します。つまり、void f(int *input) { ... }があるとすると、f(arr[0])もf(&arr[0][0])もOKです。 - 詳しくはチートシートをどうぞ
-
3次元配列のポインタとかはどう記述すればよいですか?
int (*p)[2][2] = {...};ですか?その場合、幅は2×2×sizeof(int)=16ですか?- はい、そうです
-
演習をしている中でこんがらがってしまったのですが、
int (*p)[3]; p = arr;と宣言した時には、arrやpはint三つ分を指し示すポインタで、値としては、その先頭アドレスを指し示す(arr[0][0]のアドレスを指し示す) でdouble avg_mat2(int *mat, int num_element)と宣言した時には、&arr[0][0]はint一つ分を指し示すポインタで値としてはa[0][0]のアドレスで、arr[0]もint一つ分を指し示し、その値としてはa[0][0]を指すということであっていますか? (同じような質問を繰り返してしまってすみません。)- 「 ... しては
a[0][0]のアドレスで、 」 ここまでは合ってます 「arr[0]もint一つ分を指し示し、その値としてはa[0][0]を指すということであっていますか?」 ここは違います。arr[0]は「int3つ分の配列」です。詳しくはチートシートをどうぞ。
- 「 ... しては
-
$ gcc myecho.c -o myechoと打つと$ ./myecho hoge 123としないとコンパイルされないのですが、$ myecho hoge 123でコンパイルするにはどうしたらいいですか?- タイポでした。
./myechoが正しいです - ちなみに、ドットスラッシュなしでもやるには、例えば、
export PATH="$PATH:./"のように自分の位置のpathを追加すればできます(これはよくないやり方ですが)PATHと言うのは、ターミナルから何かコマンドを実行するときに、ターミナルが見に行ってくれる場所のことです。echo $PATHで確認できます。それを見てわかる通り、重要そうなシステム中のbinディレクトリとかになっています
- タイポでした。
-
あまり関係ないんですがfor分の後のi++,++iはどちらのほうがいいとかありますか?
- どっちでもいいですQ&A の Week2の 「for文の中を++iと書いているのは何か理由がありますか?何となi++の方が馴染みがあるのですが…」を参照
Week5の宿題¶
- ごめんなさい宿題の想定入力・想定出力にかなりタイポがあってしまいました。。。以下のように修正でお願いします。
- 1問目の想定出力の2ケース目が main1.c となってしまっている -> タイポです。正しくは以下です
$ gcc main1.c -o main1 $ ./main1 12 56 34 12 34 56 $ ./main1 5 4 3 2 1 0 <- ここがmain1.cになってしまっていました 0 1 2 3 4 5 $ ./main1 8 8 3 3 8 8 $ ./main1 10 0 10 0 0 0 10 10 - 2問目の想定出力が全てmain1 となってしまっている
$ gcc main2.c -o main2 $ ./main2 abc de fghi <- 実行バイナリが全て「main1」になってしまっていました。正しくはmain2です de abc fghi $ ./main2 horse dog cat dog cat horse $ ./main2 a xxx a xxx a a xxx xxx - 4問目の想定出力には check dot: check copy: check transpose: が入っているが、元のコードには書かれていませんでした。なので、これは
main4.cを以下のようにしてください// Check dot double ret[D][1]; dot(D, D, 1, A, x, ret); // ret = A * x printf("check dot:\n"); // !!!!追加!!!! print_mat(D, 1, ret); // Check copy double ret2[D][1]; copy(D, 1, ret, ret2); // ret2 = ret printf("check copy:\n"); // !!!!追加!!!! print_mat(D, 1, ret2); // Check transpose double ret_t[1][D]; transpose(D, 1, ret, ret_t); // ret_t = ret^T printf("check transpose:\n"); // !!!!追加!!!! print_mat(1, D, ret_t);
- 1問目の想定出力の2ケース目が main1.c となってしまっている -> タイポです。正しくは以下です
-
5問目の十分大きな k はこちらで自由に決めて良いのか。
- これは自由に決めていいです。今回の例ではそんなに大きくなくて大丈夫です
-
最後の課題で値が発散する
- kを小さくしてみてください。今回の例では小さいkで答えが出ます。kを大きくしすぎると発散するかもしれません。 そんなにkを大きくしていないのに発散してしまう(つまり、答えが出ずに発散する)場合はコードが間違っている可能性が高いです
-
型について
- 今回の課題の行列の設計はnumpyと異なるので注意してください。numpyは要素3のベクトルを作るときに以下のようになります。
すなわち、 (3, ) という一次元の型を特に何も考えずにとれるようになっており、それと二次元の型 (1, 3) の変数の和が計算できるようになっています。今回は、そうではなく、単純に全て二次元配列で表現しなければならないので、注意してください。
a = np.ones(3) a.shape # (3, ) まだ縦とも横とも言っていない a.ndim # 1 つまりこれは一次元配列 a # array([1., 1., 1.]) b = a.reshape(3, 1) b.shape # (3, 1) 縦3、横1の縦ベクトル b.ndim # 2 つまりこれは二次元配列 b # array([[1.], # [1.], # [1.]]) c = a.reshape(1, 3) c.shape # (1, 3) 縦1、横3の横ベクトル c.ndim # 2 つまりこれは二次元配列 c # array([[1., 1., 1.]]) # 何も考えなくてもnpが良い感じにやってくれる a + c # [[2, 2, 2]] - ちなみに、行列計算はpythonしかやったことがないという人(結構多いと思います)は、上記のnp表記が数値計算における常識だと思っている人が結構いると思うのですが、上のような (3, ) という表現を導入しているのは単に numpyがそうしているというだけ です。 例えばpython vs matlab vs juliaのチートシートの 1d array: size (n, ) の部分を見てもらうとわかるように、matlab (これは最も広く使われている商業の数値計算言語です)ではそのような概念はありません。
- 今回の課題の行列の設計はnumpyと異なるので注意してください。numpyは要素3のベクトルを作るときに以下のようになります。
-
./a.out aに対し、以下の%cがダメなのはなぜでしょうか?printf("%s\n", argv[1]); // OK printf("%c\n", argv[1]); // ダメargv[1]は文字列(charの配列)の先頭アドレスへのポインタです。一方、%cできるのは単なる整数です。なのでダメです。以下を参照argvに何が入るかについては、この最初の図をよく眺めてみてください// 復習 char str[] = "a"; // {'a', '\0'} と同じ printf("%s\n", str); // strは文字配列の変数名すなわち文字配列の先頭アドレス。%sはchar配列のアドレスを受け取り、'\0'が出るところまでをprintする // strはアドレスなので、直接%cでprintできない。 printf("%c\n", str[0]); // %cでprintできるのは単なる整数 printf("%s\n", argv[1]); // 「a」 argv[1]は文字配列の先頭アドレスを示すのでOK printf("%c\n", argv[1]); // warning. アドレス(ポインタ)を直接%cはできない printf("%c\n", argv[1][0]); // 「a」。OK。文字列の先頭、すなわち単なる整数
Week6¶
-
Googleのツアーは希望者の参加という理解で大丈夫でしょうか(全員参加ではないということ)
- はい、希望者のみです
-
Googleツアーを申し込んだ際、確認メールは来ますか
- 来ないようです。ちょっとGoogle側とやり取りしてみます。
-
define N 3のようにすると、int a[N]は可変長配列ではなくなりますか?- はい、可変長配列ではなくなります。
defineはコンパイルの前に変数を数字で置き換えるものです。なのでint a[3]と同じになります。#include <stdio.h> #define N 3 int main() { // これはOK。Nは3に書き換えられるので、int a[3]と同じ int a[N] = {1, 2, 3}; // これはダメ。可変長配列なので初期化表記をできない int M = 3; int b[M] = {1, 2, 3}; }
- はい、可変長配列ではなくなります。
-
インスタンスを宣言した時にメモリが確保されるとおっしゃっていたと思うんですが、ポインタ変数を宣言した時には何のサイズのメモリが確保されますか?具体的には
struct point* pt;のようにある構造体のポインタを宣言した時は何が確保されるんですか?- ポインタは常に8バイトです(64ビットマシンの場合)
-
ポインタがアドレスを指しているのでその大きさは必ず8バイトになるのはわかるのですが、そのポインタがどの型のポインタであるかという情報はどこに保存されているのでしょうか
- コンパイル時にコンパイラは各変数の型の情報を知ることができます(
int *xだったら、xはint型ポインタ)。なので、外部にそういった情報を保存しなくても、コンパイラはポインタが指す型情報を認識できます。
- コンパイル時にコンパイラは各変数の型の情報を知ることができます(
-
C++で通常の関数ではなく構造体の中の関数を使用すると、どのような利点がありますか。
- 情報がその構造体だけで完結するのでわかりやすくてうれしい、というのが一言の答えだと思います。
-
構造体とは関係ないですが、string.hのstrcpy関数はshallow copyですか、それともdeep copyですか?
- deep copyです。文字列のシャローコピーは、アドレスの付け替えに相当します
-
構造体のコピーがdeep copyであるべき理由がわかりませんでした。shallow copyでも良いし、むしろshallow copyの方が良いとも思えるのですが、そうすると何が不都合なのですか。
- 根本的な理由はわかりませんが、例えば
Point ptのようにいくつかの小さなプリミティブ型(int, doubleなど)をまとめた構造体の場合は、ディープコピーのほうが何かと嬉しそうですよね。その延長だと考えられます。どうやらC言語は配列はプリミティブな型の集合でサイズが大きくなるからディープコピーしない、構造体はintやdoubleなどのプリミティブな型を新たに定義するようなものなので、intやdoubleと同様にコピーする、という思想をもっているように感じます。
- 根本的な理由はわかりませんが、例えば
-
授業に関係ないので余裕があったらで良いのですが、母(文系)が最近プログラミングに興味を持っているので、先生おすすめの本やサイトがあれば教えてください。
- ドットインストールは短くて日本語なのでおすすめではあります。自分が受講したことはないのですが、ドワンゴのコースは「ウェブサービスを作る」といった目的意識があって面白そうだなと思ったことがあります。
- 書籍で言うと、個人的にはB3のときにC言語を学んだ次にスクリプト言語を勉強しようとなって偶然手に取った初めてのPerl(超ロングセラー本)は非常に面白く、Linuxの原理などにも触れられており勉強になりました。しかし今新しくPerlを勉強する必要も低いと思いますので、何か簡単なPython入門書を買って読んでみるといいかもしれないです。Python入門書としては、自分は入門 Python 3を写経して覚えましたが、初心者であればもう一段階簡単そうな本でいいと思います。
-
関数型言語をひとつ学んでおくとよいと聞いたのですが、どの言語がいいでしょうか
- わかんないです。。。Haskell?eeic 4年のプログラミング言語の講義ではOcamlが使われているそうです
-
ここでの1の型はcharですか?intですか?
- ここではintです。今回の議論ではこの型は何でも問題ないです(ucharとして扱われるべきときがきたら、適切に上位のビットが消えるだけなので)
-
写経の時に引数とかが衝突する。
- 例えば次のようにスコープを人工的に作ると、変数名が衝突しません
int main { { int a; } { int a; // OK! } }
- 例えば次のようにスコープを人工的に作ると、変数名が衝突しません
-
独学で新しい言語を習得するときなど、授業における課題のような演習がない中でどう演習をすればよいのでしょうか?今後のために先生は普段どうなさっているのか伺いたいです。
- 自分は写経が好きなので、入門書やチュートリアルを読んで写経します。
-
if (a & 1 << i) { ... }のところなのですが(a>>i & 1)の方が0,1が返ってくるので使いやすいように思うのですが(a & 1 << i)の方がいい理由などあるのでしょうか。a = 0b100, i=2のときなどは(a>>i & 1)=1に対し(a & 1 << i)=4で扱いにくそうという意味で質問させていただきました- まず
1 << iは慣用表現のようなものなので、わかりやすい記述になっている気がします。次に、a & 1 << iだと、その結果は実際に反応した位置にビットが立っているので、0/1で返すよりも情報が含まれていると言えます。
- まず
-
プログラミングにオススメのパソコンありますか?
- 個人的には、windowsのノートPCだとThinkpad X1 carbonがノートパソコンとしては一番堅牢な気がします。あるいは、Surface Pro 7のような、フラグシップSurfaceモデルもオススメです(論文を読むときに軽くてタッチでスクロールできていいです)
-
やっとくべきプログラミング言語はなんですか?
- とりあえず
C/C++とスクリプト言語を何かひとつ(Pythonが丸いか)、およびシェルスクリプトは知っておくといいと思います。あとウェブ系(javascript)でしょうか。分野によってはMATLABが必須かもしれないです。新しい言語を学ぶ必要が発生したときに、ひるまないようになっておけば大丈夫です。
- とりあえず
-
今後、matlabをたくさん使う授業はありますか?
- 制御系の実験などでは使うような気がします。そんなに多くはないです。
-
Rを使うことはありますか?
- 自分のこれまでの人生ではRを使う機会はありませんでした。統計に強い言語なので、統計をたくさんやる人は使うかもしれません。
-
ポインタが指す構造体のメンバ変数にアクセスするときは、
どちらの表記が好ましい(あるいは一般的、おすすめ)ですか。 また空白を授業の手本に倣って入れるようにしたいのですが、(*q).x q->xのどちらが良いですか。q->x q -> x- アロー演算子(
q->x)を使う方がいいです。(*q).xという表記がわかりにくいため、アロー演算子が準備されているのだと思います。また、アロー演算子を使うと、「qはポインタだ」ということが自明にわかるので、良いと思います。ドットを使う場合、もし*qの部分が複雑だと、ポインタにアクセスしているのかどうかわかりにくい場面があると思います。 - 空白は入れないほうがオススメです。次の「保守性4.1」を参考にしてください。【改訂版】組込みソフトウェア開発向け コーディング作法ガイド[C言語版]
- ちなみに今のリンクは実際にCを書く人むけに、オススメなわかりやすい書き方をまとめたようなものです(海外の規約文章をまとめたようなものになってます) Cを一通り勉強した今の皆さんであれば結構楽しめると思いますので、パラパラ読んでみてもいいかもです。講義で習った内容も、「使うな」とか書いてあったりします(Cの機能なので知る必要があるが、古かったりわかりにくい機能なので業務では使うべきではない、というような内容)
- アロー演算子(
Week6の宿題¶
-
宿題4はビット演算を使わないでコードを書いてもよいのでしょうか?
- できればビット演算を使ってほしいです。
-
宿題3について質問があります。
Flush: 5枚のカードの色が同じ。数字は問わないとありますが、wikiには同じスートとの記載があります。また、想定出力も同じスートであることを前提としているように見えます。スートと色、どちらが正しいでしょうか?- ごめんなさい、「同じスート」が正しいです。普通のフラッシュです。
-
宿題3の想定入力の2個目で、カードが6枚与えられてしまっていると思います。
- ごめんなさい、タイポです。正しくは以下です。
$ ./main1 h10 s10 d2 h2 c3 [h 10] [s 10] [d 2] [h 2] [c 3] [c 3] [d 2] [h 2] [h 10] [s 10]
- ごめんなさい、タイポです。正しくは以下です。
2・3年生向けオススメ本¶
- すぐには読まなくてもいつか参考にさせていただきたいので、先生のおすすめの本をslackとかにまとめていただけると嬉しいです。
- 以下は、本講義で学んだC言語を踏まえて、C++を学ぶための本です
- ストラウストラップのプログラミング入門(ビャーネ・ストラウストラップ ):C++を作ったストラウストラップ先生による、大型の入門書です。これを一冊読み切ればだいぶC++のことがわかると思います。最近はストラウストラップ先生のこちらの本(未読)のほうが評価が高いようなので、そっちでもいいかもしれません
- C++のためのAPIデザイン(マーティン・レディ):クラスをどう設計すればいいかについて、現実の例題をあげながら解説してくれます。自分は今でもクラスを書き始めるときはこの本を見ます。
- Effective Modern C++ ―C++11/14プログラムを進化させる42項目(Scott Meyers):C++11以降の書き方についての解説です。知識がC++11以前で止まっている人には、よい勉強になります。
- Modern C++チャレンジ ―C++17プログラミング力を鍛える100問(Marius Bancila ):C++17という新しいC++の機能を用いて、pythonの文字列関数のような便利機能を順番に実装していってくれます。この内容を知っておくと、いつか役立つかもしれないです。
- STL―標準テンプレートライブラリによるC++プログラミング(ディビッド・R. マッサー):C++ではデータの表現とアルゴリズムとしてSTLという機能を使うのですが、書き方にクセが強く、初見殺しです。この本はSTLの書き方と思想について延々と説明されています。キツかったですが、松井はこれを読んでSTLの基本が理解できました。
- 以下は、プログラミングに関係して使う数学、最適化、アルゴリズムに関するものです。今後皆さんが進む分野を問わず、勉強になると思います。
- 線形代数とその応用(ギルバート・ストラング):MITの有名教授のストラング先生による、線形代数の本です。線形代数で悩んだらこの本を最初から読んでみると良いです。ストラング先生のMIT Open Coursewareもオススメです。最近ストラング先生の大型本も発売された(こちらは未読)ので、そっちも良いかもしれません。
- 統計のための行列代数 上・下(D. A. ハーヴィル):これは線形代数の辞書です。行列を使った演算の式変形でわからないことがあればこれを見ると載っているので、辞書として一冊持っておくといいかもしれません。
- これなら分かる最適化数学―基礎原理から計算手法まで(金谷健一):皆さんはそのうちPrincipal Component Analysis; PCA(次元削減)という技術を習うのですが、その数学的背景として一番わかりやすいです。この本に限らず、金谷先生の本は、工学系学生に対する実用的な手法の解説で勉強になります。
- しっかり学ぶ数理最適化 モデルからアルゴリズムまで(梅谷俊治):最近発売されて話題になっている、最適化全般に関する入門書です。積読でまだ読んでいないのですが、梅谷先生のスライドは非常に勉強になるので、おそらくこの本も面白いです。
- アルゴリズム設計マニュアル 上・下(S. S. スキーナ):アルゴリズムの本はたくさんあるのですが、これは語り口が軽くて読み物としても楽しめる名著です。
- 数値計算の常識 (伊理正夫、藤野和建):数値計算という概念に対する心構え。古いし短いのですが非常に勉強になります。
- リーダブルコード ―より良いコードを書くためのシンプルで実践的なテクニック(Dustin Boswell):有名な、コードの書き方のアドバイス本です。すぐ読めるのですが、コーディングを良くする関する基本的な方向性が書かれているので、勉強になります。
- 以下は、文章校正やスライドデザインに関するものです。これは研究室配属された卒論生には読むように推薦しています。
- 理科系の作文技術 (木下是雄):アカデミックライティングの基礎。薄い新書だが基本中の基本なので必読です。
- ノンデザイナーズデザインブック (Robin Williams):デザインの非専門家向けの、デザイン指南書。スライドやポスター作りの際に気をつけるべき基本原則が書いてあります。
- 伝わるデザインの基本 (高橋佑磨、片山なつ) :これもデザインの基本。有名ホームページの書籍版。日本語のデザインにも対応してます。
Week7¶
-
オクトキャットもマイクロソフトのものになってしまったのですか
-
ls -alすると.gitはディレクトリ直下にあることになっているのですが、手元のFinderから見ることができません。.gitはどこから見れますか。(Macです)- 隠しファイル(ドットから始まるファイル)は見れない設定になっているのだと思います。ただ、command + shift + .(コマンド + シフト + ピリオド)でみることもできます。
-
ユーザ名とパスワードを求められなかったのですが、いつも求められるわけではないのですか。
- 求められないこともあります(設定による)
-
やってみようの最後の説明の、pushを行いますとありますがpushはどうすればできるのですか
- まだpushはしなくていいです
-
「.」と「..」という2つのファイルがありますが、これにはどんな役割がありますか
.は現在位置という意味で、..は一個上という意味です
-
パスワードを打ち込む前に、repl.it がフリーズしたので更新してもう一度git cloneを入力しようとしたらfatal: destination path ‘simple_calc’ already exists and is not an empty directory.と表示されるのですがどうすればよいでしょうか
- これは既にcloneされているか、されている途中で失敗しています。一回simple_calcディレクトリを消して、やり直してください
-
Usernameは打ち込めるのですが、passwardを打ってもコマンドラインに表示されなくて困っています
- コマンドラインには表示されないです。そのまま打ってエンターしてください
-
ユーザ名とパスワードをが必要ないのは、
.gitconfigという認証ファイルが作られてるからだと思いますが、どうでしょうか?- httpsではなくsshベースで接続すると、ユーザ名・パスワードを求められません。ほかにも、キャッシュを設定することができるようです
-
githubのリポジトリの消し方は?
- GitHubのウェブ画面上から、Settings -> Danger Zone - > Delete this repositoryとして、そのリポジトリ名を入力すれば、消せます
-
ls -alで表示されるものがどんなことを表しているかがよくわからないので、教えて欲しいです。- パーミッションなどが表示されています。読み方はこちらを参照。先頭のパーミッション部分についてはこちら
-
今後プログラムを書くときは、その都度GitHubでレポジトリを作ってバージョン管理をするべきという理解でいいですか。
- そうですね。例えば課題であれば、課題1つにつき1ちリポジトリを作る、とかでいいです。あるいは、講義1つにつき1つのリポジトリを作り、その中にディレクトリを作りわけていくとかでもいいです。プライベートで作れば誰にも見られないので、とにかくカジュアルに息を吸うようにリポジトリを作ってgit管理するといいと思います。
-
ローカルの.git を消す→GitHubリポジトリを消す と書いてありますが、この手順は逆にするとまずいのですか?
- どっちでもいいです
-
Githubで名前などを変更した場合、ローカルには反映されるのでしょうか?
- ローカルには反映されないと思います。
-
replitではできたのですが、ローカルでやろうとするとRepository not foundとなってしまいました
- これ何かおかしいですね。。。clone URLをもう一度確認してみてもらえますか?
-
Repl.it の場合は適当なreplsを作ってそこにcloneするという認識でよろしいでしょうか.
- 普段使っているプライベートのやつを使ってOKです。そっちを汚したくなければ、別のものでもいいです
-
Git commit をはじめて使用するときに入力するメールアドレスは、githubに登録したものを使用するのでしょうか。また、このアドレスに更新履歴が届いたり、このアドレス(また、名前に関しても)をgitにおいて変更、消去できるのでしょうか
- GitHubに登録したものであってもなくても大丈夫です。この名前・アドレスは、コミットの情報に紐づきます。なので、あとでもし誰かがgit変更履歴を見たとすると、その名前・アドレスが見えます。更新履歴の通知が届いたり、変更・消去などとは、関係ない(はず)です。そういったことは、GitHubの登録アドレスで行います。結論としては、ここは何でもあまり問題にならないです
-
以下のようなエラーになります。どうすればいいでしょうか?
Username for 'https://github.com': hoge Password for 'https://hoge@github.com': remote: Invalid username or password. fatal: Authentication failed for 'https://github.com/hoge/simple_calc.git/'- これはタイポの可能性が高いです
-
Gitのローカルディレクトリのsample_calcを消そうとして、rm -r sample_calcと入力すると、override r—r—r—というようなものが表示されて、うまく消すことができないのですが、どうすればよろしいでしょうか?
- rm -rf でどうですか?
-
ローカルでやってるんですけど、readmeに変更を加えてみるとは、github上でですか?ローカルでですか?github上で変更してから、addしてstatusみたところmodifiedになりませんでした
- ローカルでお願いします。いったんローカルのディレクトリを消して、再度cloneするのをおすすめします(たぶんいまはgithubのほうが進んでいる形になっているので)
-
git logで更新ログを見たところ、最後に(END)と出てきたのですが、このあとどうすればよいでしょうか
- たぶん長すぎて表示できていないのかもしれません。「下キー」を押してみてください。終了するときは「q」を押してください
-
commitをした時自動的にメールアドレスと名前が入れられて、何も入力せずにcommitできてしまったんですが、それで大丈夫ですか
- 大丈夫だと思います。どちなみに、以前gitを使ったことがあるなら、そのときの設定が残っているのだと思います
-
このようになりましたが大丈夫でしょうか
Your name and email address were configured automatically based on your username and hostname. Please check that they are accurate. You can suppress this message by setting them explicitly. Run the following command and follow the instructions in your editor to edit your configuration file: git config --global --edit After doing this, you may fix the identity used for this commit with: git commit --amend --reset-author- 名前などが自動設定されたっぽい、というメッセージです。これでよいと思います。
-
Repl.it で該当のreplを開き直すとreadmeが消えてしまいますが仕様ですか.
- これが多分repl.itの謎仕様です。再度やり直してみてください。。。。
-
git statusをしたところ
と出ましたが大丈夫でしょうかUntracked files: (use "git add <file>..." to include in what will be committed) main.c nothing added to commit but untracked files present (use "git add" to track)- これはまだgit add してないって意味ですね。git add main.c をして、次にすすめます
-
replit上でEditが見当たらずReadMeの編集の仕方がわかりません
- 真ん中の編集画面の右上の「edit」を押してください
-
commitのとき登録するメールアドレスを変更するにはどうしたらいいですか?
- /home/runner/.gitconfig あるいは /home/ユーザ名/.gitconfig を直接編集してもOKですし、コマンドでやるにはここを参照 どうやら設定の時と同じコマンドで更新できるようです
-
何ステップか前に戻すロールバックはどうやって行えばいいですか
- checkoutというコマンドを使います。詳細はググってみてください。一番簡単なのは次の例です。朝起きて
git pullしてmain.cのコーディングを初めて、しばらくしたらこれは全部ダメだ消そう、と決意する。このときは、$ git checkout main.cで朝の状態に戻せます。ただしこの場合は朝からいままでやってきた作業は消失するので注意してください。
- checkoutというコマンドを使います。詳細はググってみてください。一番簡単なのは次の例です。朝起きて
-
この授業のリポジトリで、先週の課題をコピペではなく、試しにpushしてみても良いでしょうか?
- はい、何をしてもOKです
-
すみません、課題の提出をpushしても良いかという趣旨でした。
- はい、コピペの部分はいつでもgitに置き換えて大丈夫です。repl.itの謎挙動にだけ注意してください
-
GitHubの方で編集した後にpull をせずにローカルでも編集してしまい、衝突してしまった場合にはどうすれば良いですか?
- エラーメッセージにどうすればいいか書いてある場合は、それに従ってください。
- そうではなく次のようなエラーになった場合、これは「GitHubのほうが進んでいるのでpull出来ません」と言われています。
以下が一番簡単な手動修正です(この一番簡単で泥臭いやり方がなぜかウェブ上ではあまり検索しても出てこない気がします。こうすればうまくいくことを理解してから、ちゃんとしたgitコマンドの扱いを学んでいけばいいと思います)
$ git pull origin main Username for 'https://github.com': XXX Password for 'https://XXX@github.com': remote: Enumerating objects: 8, done. remote: Counting objects: 100% (8/8), done. remote: Compressing objects: 100% (6/6), done. remote: Total 6 (delta 0), reused 0 (delta 0), pack-reused 0 Unpacking objects: 100% (6/6), 1.36 KiB | 695.00 KiB/s, done. From https://github.com/XXX/simple_calc * branch main -> FETCH_HEAD 9ea0035..61ad33d main -> origin/main Updating 9ea0035..61ad33d error: Your local changes to the following files would be overwritten by merge: README.md Please commit your changes or stash them before you merge. Aborting- 状況:手元の
README.mdよりもGitHub上のREADME.mdのほうが新しくなってしまい、git pullしてもエラーになる - まず手元で編集していた
README.mdをREADME.md.bkとリネームする。こうすると、現在ディレクトリ上にはREADME.mdはもう存在しませんね。 - ここで、
$ git checkout README.mdとする。ここでのcheckout XXXは、「XXXを変更履歴に記録されている最新の状態に戻せ」という意味です。こうすることで、変更前のREADME.mdが復活します。最新というのは、「手元の変更履歴で」最新という意味です。まだGitHubの最新変更は反映されていません。 $ git pull origin mainとする。こうすると、GitHubの方の最新の変更が手元に反映されます- さっきの
README.md.bkの内容をあらためてREADME.mdにコピペし、変更を進める。こうすると手元の変更が最新になります。
- 状況:手元の
-
git status に対してon branch masterといわれたのですが, on branch main に移る方法はありますか
- ブランチ名がmasterになってしまっている?ようです。ブランチを作ればいいのですが、より簡単なのは全て消してcloneからやり直すことです。
-
password が自動的に入力されて、変更できない状態になってしまいます。調べたところ、ssh接続のようなものをしないといけないらしいのですが、そうしたほうがよいですか?
- ちょっとわからないです。。。replitを使っているなら、新しいreplを作ってみてください
-
先週の課題が反映されないのですが、なぜでしょうか?
- pushしてますか?
-
余談ですが、git initして.gitを作成した後にgit statusを実行すると、On branch masterという表示が出ました。(ローカル環境です)
- どうやら手元のgitのバージョンを2.28.0に上げる必要があるようです。そうでない場合、
git initで作られるものはデフォルトブランチはmasterのままのようです。
- どうやら手元のgitのバージョンを2.28.0に上げる必要があるようです。そうでない場合、
-
c言語の乱数はこれはメルセンヌ・ツイスタですか
-
このwebページはいつまで残りますか
- ずっと残ります
-
関係ないことなのですが、授業のホームページはどうやって作っているのでしょうか。
- MkDocsという、マークダウンをhtmlに変換する仕組みです。それに、Material for MkDocsというものをかぶせています。田浦研とか、産総研のスパコンのABCIのドキュメントも同じ仕組みです。それをgithub pagesでホストしています
-
環境構築がよくわかっていないのですが、環境構築はどのように学ぶのが良いでしょうか?
- 三年で色々やると思います。とりあえず素のlinuxの仕組みをいろいろ試行錯誤しながら学べばいい気がします。
- linuxの文化では、ホームディレクトリ(
/home/matsui/)直下に、先頭がドットから始まるディレクトリあるいは設定ファイル(ただのテキストの場合が多い)を置いて、そこに設定を書き込むことで設定を管理したりします。例えば(流派によりますが)emacsの設定情報を/home/matsui/.emacsというファイルに書き込んだりします。これらを自分好みにカスタマイズしていくのが環境構築の一つかと思います。 - もしdockerとかのことを言っているのなら、linuxの仕組みを学ぶまでははあまり気にしなくていいと思います。
- ただし、pythonの環境構築だけは鬼門です。pythonは非常に広く使われているにも関わらず決定版というべき環境構築方式が未だに全く定まっておらず、これが初学者にとっての鬼門になっています。おそらく大学の講義でpythonを習うたびに、違った環境構築のやり方を習うと思います。pythonの環境構築回りではpip, venv, anaconda, pyenv, pipenv, poetry, pyflowなどなどがあり、訳が分からないです(表1, 表2)。個人的には、anacondaのみを使うことをオススメしています。利点と弱点は以下です。また、注意として、WSLにanacondaをいれるときはwindowsにいれるのではなくlinux版をwslに入れるようにするといいです。
- 利点:anacondaだけなのでシンプル。何か変なことがおきたらanacondaディレクトリを消せ場全て最初に戻るので、気持ちが楽
- 利点:anacondaの中にはpipも入っているので、pipも使える。pipとcondaは混ぜると危険だが、気にせずに使って、おかしくなれば全て消してやり直せばOK。
- 利点:まれにcondaにしか入っていないライブラリが存在する。それを使うためには結局どこかでanacondaを使う必要があり、そのときに一番シンプルな構成はanacondaのみの構成
- 弱点:anacondaのバイナリたちはシステムのバイナリより優先される(システムを乗っ取る)ので、関係ないc++のコーディングで悪さをしたりする(つらい) なので、anacondaにずっとついていくという覚悟が必要
- 弱点:anacondaそのものは結構サイズが大きい
- 弱点:anacondaはよく壊れるので、一年に一回入れ直すぐらいの気持ちでいる必要がある
-
プログラミング等を用いるおすすめのバイトはありますか?
- 本郷界隈の、東大生がよくいるところとかがいいかもしれない?
-
すみません、gitの話に戻るのですがanacondaやvscodeが自動的に作る
.hogehogeフォルダはignoreした方がいいですか?- anacondaが作るものは、pythonのデフォのgitignoreで既にignoreされてます。vscodeが作る設定フォルダは、git管理したい場合もあると思うので、ケースバイケースです
-
VScodeを使っているのですが、VScodeの使い方の参考などはありますか?ターミナルやデバッグなどがよくわかっていないのですが、、、
- 個人的には公式の資料をとにかく読むのがいいと思います。あとテックカンファレンスでMSの人が発表してるのを見たりすると、最新の話がわかっていいです。例えば最近あったCppCon(c++のテック会議)ではMSのVSCodeを開発している人が、VSCode + CMakeでの開発の様子を説明しています。こういうのを見るといいかもです。
-
-oのオプションを付けて実行ファイルに独自の名前をつけるとgitignoreしてくれないのですが、その場合は自分で書き足せばいいのでしょうか
- そうですね、その場合は書き足す必要があります。あるいは、出力するバイナリファイルは
binというディレクトリにまとめて入れるようにしておいて、そのbinをgitignoreすればよいです。「出力バイナリはすべてbinに入れる」と言った手続きは、Makefileというやりかたでできます。これはソフ2でやります
- そうですね、その場合は書き足す必要があります。あるいは、出力するバイナリファイルは
-
Jupyter NotebookをWSL導入前から入れていたので、CはWSLからpythonは独自のコマンドライン(?)から動かす状態になっています。WSLに統一した方がいいですか?それともこのままの方がいいのでしょうか?(授業とずれた質問ですみません)
- 個人的にはWSL統一が好きですね(自分はWSLは大好きなので。。。。。)真面目に答えると、ウインドウズネイティブ側から動く仕組みと、WSL側から動く仕組みを混ぜないほうが、変なミスを減らせて良い気がします。例えば.sshの設定とかは、気付かないでいると分断されちゃいます
-
ソフトウェア2を取っておかないと3年や4年になってしんどいとかありますか。先生の授業はわかりやすくてとても楽しかったのですが私自身の理解力不足で課題などがとても大変だったので、2はハードルが高いなと思っているのですが、、、
- 個人的には、取った方がいいような気はします
-
ソフトウェアⅡが難しいと言われてすごく怯えているのですが、(ソフトウェア1は説明が丁寧だったのでその反動もあって怖いです、、、)先生はエラーが出たり、わからないところが出たりした時は、どんな方法で大学生の時対処してましたか…?
- 友達にきいていたきがします。。あと自分は教科書を読んだりチュートリアルをやったりするのが好きなので、ひたすらやっていました。
Week7の宿題¶
-
stdio.hやstdlib.h以外もincludeしていいか?- OKです。
-
マークダウンがちゃんとレンダリングされているか不安
- GitHubのリポジトリの画面で「
instruction.md」をクリックしてみると、レンダリングされた結果が表示されます。この画面で綺麗になるようにしておいてもらえると助かります。 - 特に、プログラミングのコードを書くときは、バッククオーテーション 「`」 (windowsのキーボードだとアットマークがあるキーを、シフトを押しながら押すと出てくる。シフトを押しながら「7」を押すと出てくる普通のクオーテーションとは違う記号なので注意)を使うことでコードっぽくレンダリング出来るようになります。
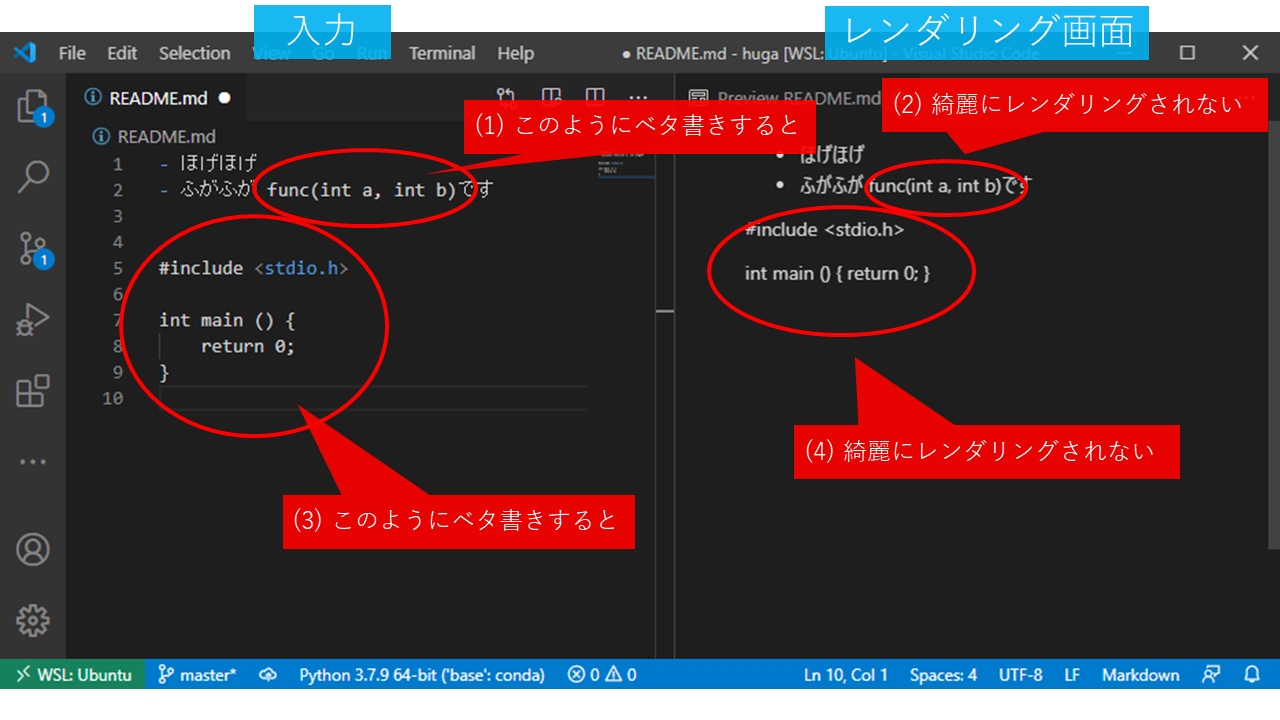
- 上の図で、左側が実際に入力する内容、右側がそれをレンダリングした画面です。このように、文章途中で何もせずにコードをベタ書きすると綺麗になりません。例:func(int a, int b)
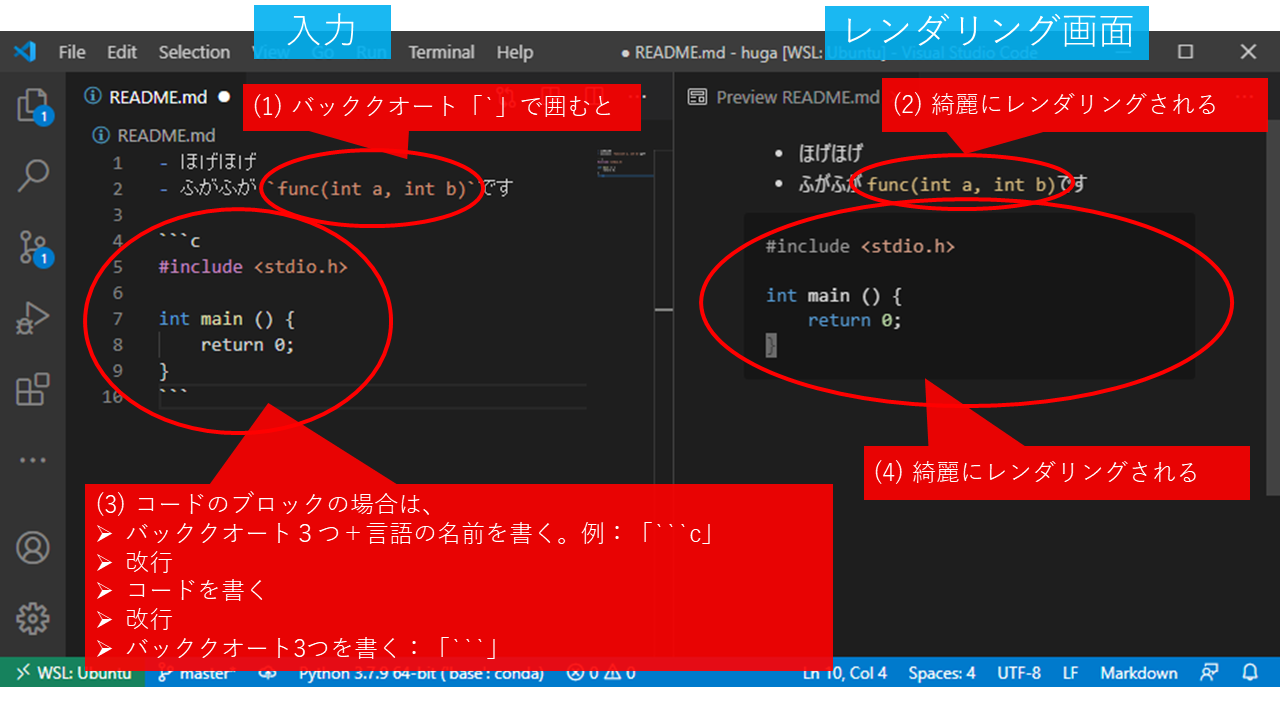
- 上の図では、コードの部分をバッククオーテーションで囲んでいます。こうすると綺麗にレンダリングされます。例:
func(int a, int b)また、コードのブロックに関しては、上の図のようにバッククオーテーション3つで囲むと綺麗になります。
- GitHubのリポジトリの画面で「
-
質問なのですが、サンプルプログラムにaが5×5で配置されていたため、2048も5×5で書いてしまったのですが、まずいでしょうか?
- 4x4でも5x5でも大丈夫です
-
最終課題についての質問なのですが、発生する数字は本来のゲームだと2がほとんどでたまに4という感じなのですが、どのようにしたらいいですか。
- 適当にランダムな設定で大丈夫です
-
GitHubのアカウント名を変えた
- 一応松井に新アカウント名を教えてください