Week 5 (2020/10/29)¶
今日やること
- ポインタのポインタ
- ポインタの配列
- 二次元配列とポインタ
- コマンドライン引数
まずはじめに¶
- 参考書の追加
- 先週のQ&Aの説明
- Googleバーチャルツアーの紹介
- week3最終課題のイケてるゲーム発表
ポインタのポインタ¶
今日はポインタの応用編をやっていきます。頑張っていきましょう。まずはポインタのポインタです。
素朴な例¶
「int型の変数を指すポインタ」を「intへのポインタ」などと呼びました。では、
「『intへのポインタ』を指すポインタ」は考えられるのでしょうか?考えられます。それがポインタのポインタです。
次の素朴な例を考えてみましょう。
int a = 10;
printf(" a: %d\n", a); // 10
int *p = &a;
printf(" p: %p\n", p); // 0xff5c (以下、アドレスは全て人工的な例です)
printf(" *p: %d\n", *p); // 10
int **pp = &p;
printf(" pp: %p\n", pp); // 0x51a5
printf(" *pp: %p\n", *pp); // 0xff5c
printf("**pp: %d\n", **pp); // 10
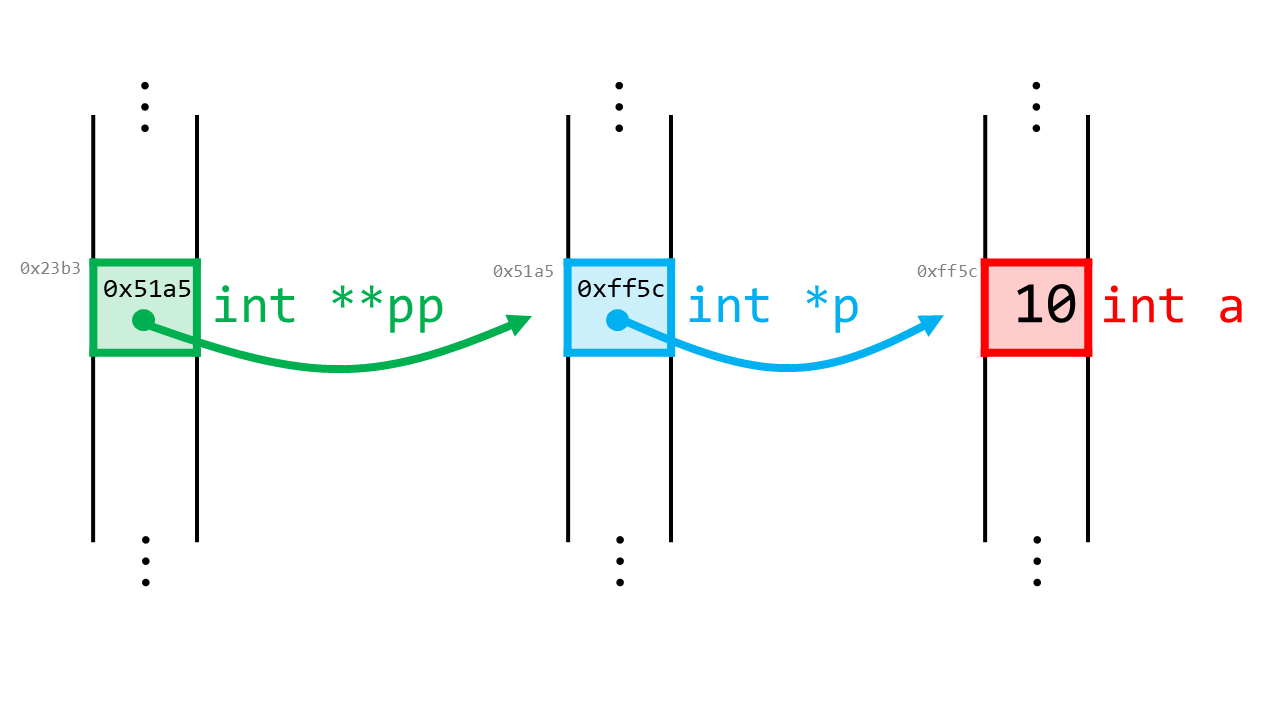
このように、int **ppとアスタリスクを2つ重ねることで、ポインタへのポインタを表現することができます。
あるポインタint *pに対し、ppにはポインタpのアドレス&pを代入します。上の表記の繰り返しですが、a, p, ppの関係は次のようになります。
aと*pと**ppは同じ値:10. 型はintpと*ppは同じ値:0xff5c. 型はint *ppの値:0x51a5. 型はint **
関数の引数としてポインタそのものを受け取る場合¶
さて、素朴なポインタのポインタを使う例を見てみましょう。ここではまず、「main側のポインタを、関数から編集する」という例を見てみましょう。
まず、配列中から一番大きい値を返すfind_largest関数を
考えます。ここでは、ポインタを用いて最大値を返しています。
ここで変数が実際にどのようにメモリ中に表現されるかを見てみましょう。
以下では、通常の変数は黒、配列は赤、ポインタは青、と色分けしています Reese, p99
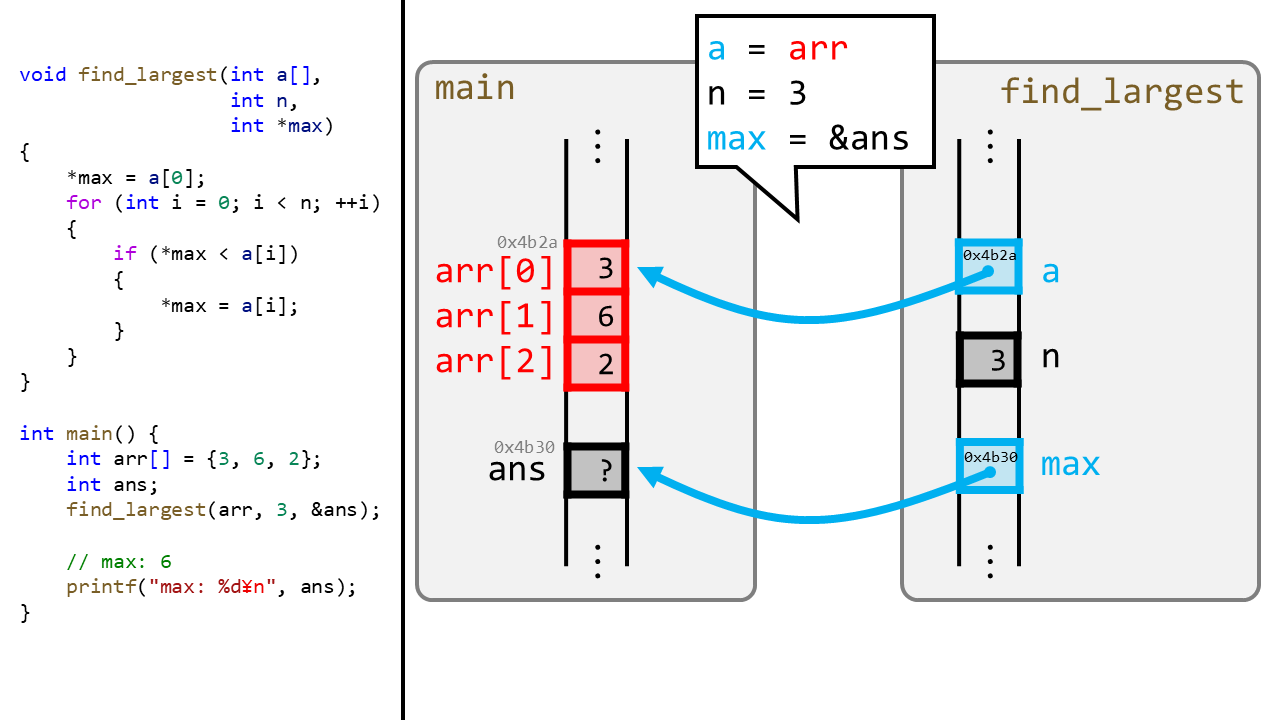
ここではいくつかのポイントがあります
mainが扱う領域と、find_largestが扱う領域は違います。そのため、main側の変数をfind_largestから変更するには、ポインタを経由する必要があります。int a[]とint *maxは、find_largest側ではどちらもポインタになっています。これは先週習った、「関数引数におけるa[]は*aに等しい」ということですね。- 関数の呼び出し時に引数の変数3つがコピーされます。このとき、配列全てをコピーしたりするわけではないので注意してください。
- 関数引数(
a,n,max)は、あくまで、関数側のメモリ領域中でのローカル変数です
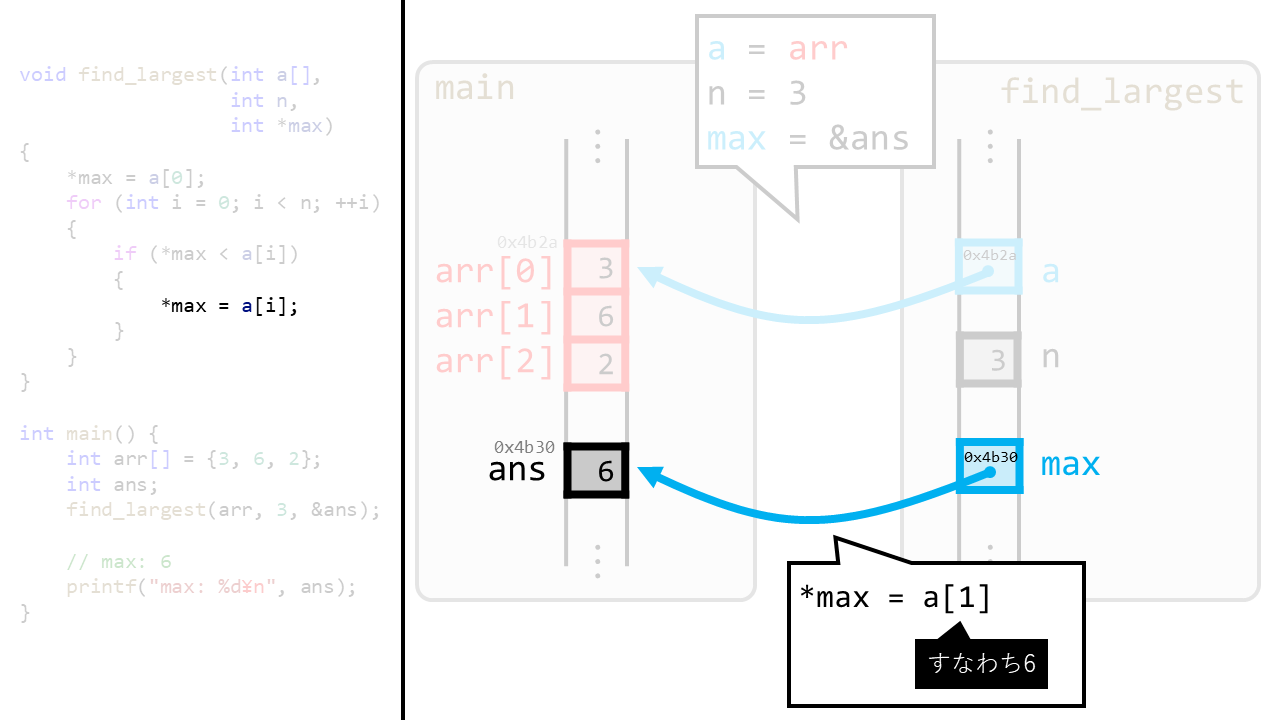
上図はmaxを経由して値を更新するときの動作です。
maxはmain側のansを指しているので、*maxという表記でansの中身を書き換えることができます。
上のfind_largestは、main側のint型変数ansに、arr[3]中の最大値を記述する関数でした。
次にfind_largest2を考えましょう。これは、
main側のint型ポインタp_ansが、arr[3]中の最大要素を指すようにする関数です。ここでは、ポインタのポインタを使います。
下図を見てみましょう。ここではポインタのポインタを緑色で表現しました。
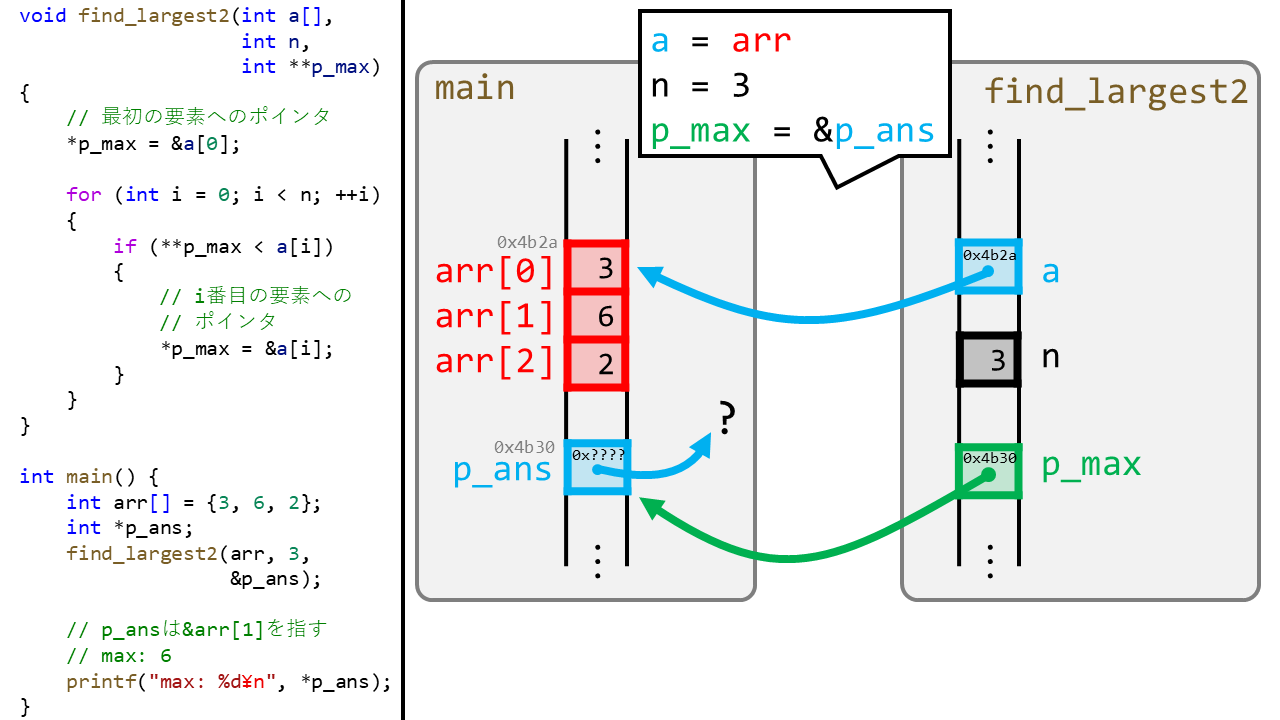
ここでは次のポイントがあります
- 基本的な構造は先ほどの
find_largestと変わりません。 find_largestでは関数側のint *maxがmain側のint ansを編集しました。つまり、intを編集するためにポインタを使いました。一方、find_largest2では、関数側のint **p_maxがmain側のint *p_ansを編集します。つまり、intポインタを編集するので、intポインタのポインタを使いました。
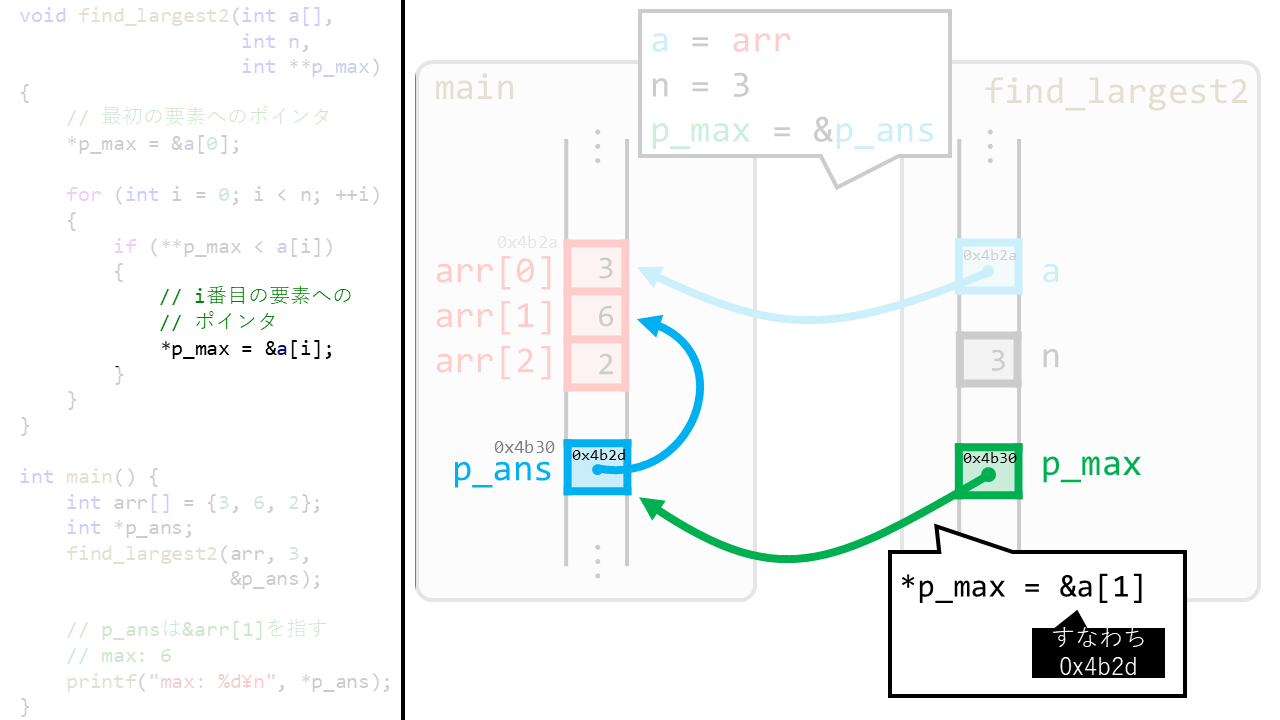 実際に
実際にp_ansを編集するときの挙動が上の図になります。p_ansには、arr要素中で最大のものアドレス(&arr[1])を代入しています。
このようにして、「main側のポインタ」を編集する際に、関数側では引数として「ポインタのポインタ」を使う場合があります。 ポインタのポインタを扱う例は他にもあり、最も使う例として「ポインタの配列」があります。それを次章で見ていきましょう。
やってみよう(20分)
上記を写経してみましょう
クイズ
int *maxを引数にとるに対し、最大値を直接、値としてreturnするvoid find_largest(int a[], int n, int *max) { ... }を書いてみましょう。つまり、次のような使い方になります。int find_largest_(int a[], int n) { ... }これは簡単ですね。int ans = find_largest(arr, 3);int **p_maxを引数にとるに対し、最大要素へのポインタ(アドレス)を直接値としてreturnするvoid find_largest2(int a[], int n, int **p_max) { ... }を書いてみましょう。int *find_largest2_(int a[], int n) { ... }
答え
- 例えば以下。
ここでポイントは、ある型
int find_largest_(int a[], int n) { int max = a[0]; for (int i = 0; i < n; ++i) { if (max < a[i]) { max = a[i]; } } return max; } int main() { int arr[] = {3, 6, 2}; int ans1, ans2; find_largest(arr, 3, &ans1); ans2 = find_largest_(arr, 3); printf("%d %d\n", ans1, ans2); // 6 6 }Tの変数xを変更したいとき、次の二通りがあるということです。void f(T *x) { ... }ポインタとして変更T f() { ... }直接return
- 例えば以下。
ここでポイントは、ある型
int *find_largest2_(int a[], int n) { int *p_max = &a[0]; // 最初の要素へのポインタ for (int i = 0; i < n; ++i) { if (*p_max < a[i]) { p_max = &a[i]; // i番目の要素へのポインタ } } return p_max; } int main() { int arr[] = {3, 6, 2}; int *p_ans1, *p_ans2; find_largest2(arr, 3, &p_ans1); p_ans2 = find_largest2_(arr, 3); printf("%d %d\n", *p_ans1, *p_ans2); // 6 6 }Tへのポインタ変数pを変更したいとき、次の二通りがあるということです。void f(T **p) { ... }ポインタとして変更。つまりポインタのポインタを用いるT *f() { ... }直接return
このように思考を整理しておくと、ソフトウェア2でmallocや線形リストといった、ポインタを駆使する概念を習うときに役にたちます。
ポインタの配列¶
さて、それではポインタの配列を考えてみましょう。
ポインタ配列の基本¶
char s1[] = "toyama";
char s2[] = "ishikawa";
char s3[] = "fukui";
char *hokuriku1[3];
hokuriku1[0] = s1; // &s1[0]といっしょ。s1の先頭アドレスを代入
hokuriku1[1] = s2;
hokuriku1[2] = s3;
hokuriku1は配列です。そして、その要素は「char型へのポインタ」です。
そして、hokuriku1の各要素には文字列の先頭アドレスを代入にしています。これを図示すると次のようになります。
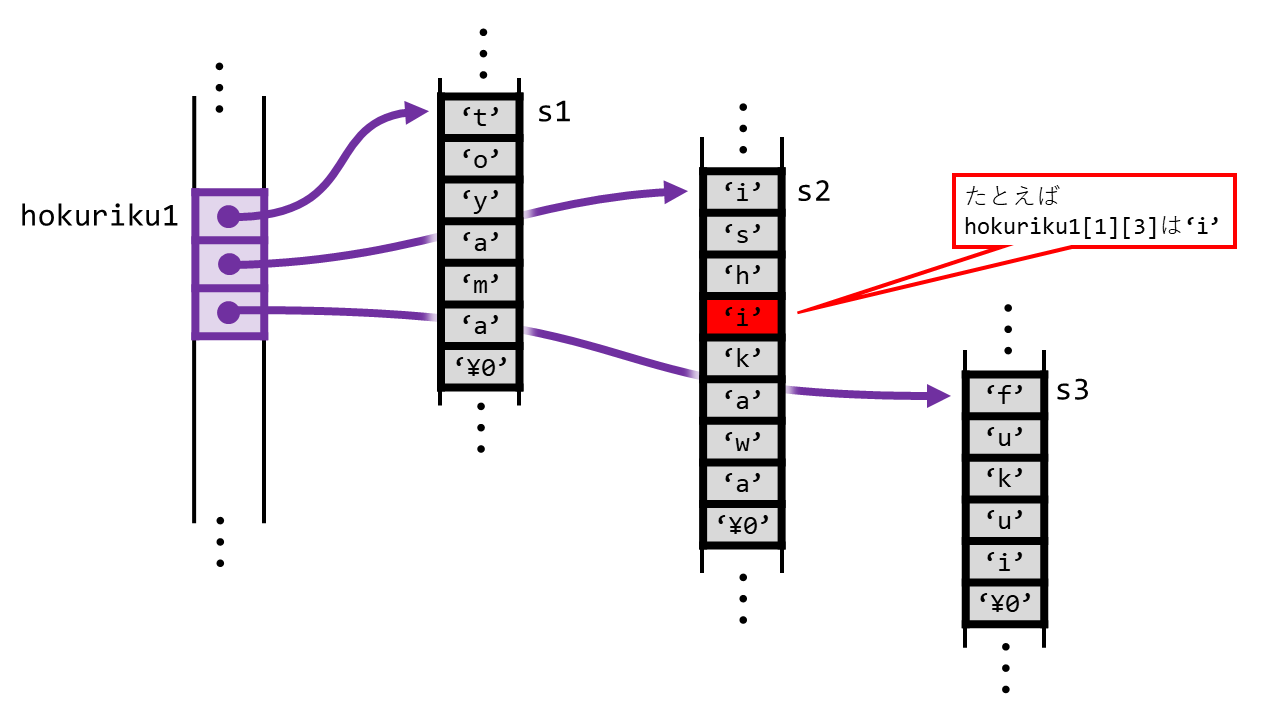 このように、文字列
このように、文字列s1, s2, s3がどこかで確保されます。そして、その先頭を、hokuriku1の各要素が指します。
hokuriku1[0]という表記がs1と同じであることを考えると、s1[0][0]hokuriku1[0][0]は't'であることがわかります。 授業後更新:s1ではなくhokuriku1でした。修正しました。
要素のアクセスは次のように書けます。
for (int i = 0; i < 3; ++i) {
hokuriku1[i][0] = 'A';
printf("%s\n", hokuriku1[i]);
}
// 結果:
// Aoyama
// Ashikawa
// Aukui
さて、このような「文字列を複数確保 + それらの先頭を指すポインタの配列」は、配列の初期化記法を用いて次のようにも書けます。
char *hokuriku1[] = {"toyama", "ishikawa", "fukui"};
コラム
なぜ初期化記法を使って作った文字列は編集できないのでしょうか?これはweek4で習った文字列の初期化
がそのまま適用されているからです。char s1[] = "toyama";のように明示的に配列を作った場合はそれらは自由に編集できます。
一方、初期化記法を用いた場合は、実は配列が確保されているのではなく、プログラムのどこかに確保されたリテラルを指しているだけなのです。
以下を実行してエラーになることを確認しましょう。
char *hokuriku1[] = {"toyama", "ishikawa", "fukui"};
hokuriku1[0][0] = 'a'; // Segmentation Fault
上記の文字列の場合は書き込みはできないものの、読み込みはできます。
一方で、文字列でない場合は、そもそも配列を確保できないので注意してください。
int *a[] = {{0, 1}, {2, 3, 4}, {5}}; // この書き方はダメ
printf("%d", a[0][0]); // Segmentation Fault
次のように、明示的に要素の配列を確保すれば、大丈夫です。
int arr1[] = {0, 1};
int arr2[] = {2, 3, 4};
int arr3[] = {5};
int *b[] = {arr1, arr2, arr3};
printf("%d\n", b[0][0]); // 0
さて、ポインタ配列の利点は何でしょうか。プログラミングを行う上で、もし全ての要素を配列や多重配列に保持できるのであれば話は楽なのですが、 ときにはそのようなことが難しい場面があります。その際に、配列の入り口だけを用意しておき、必要に応じて配列が指す先を指定する、 ということをしたい場面があります。そのときに、ポインタ配列は最適です。 その例としてスワップがあげられます。ポインタ配列の要素であるポインタは値としてアドレスを持つだけなので、要素を簡単にスワップすることができます。 これは、後述するように、二次元配列では簡単にはできません。
char *tmp = hokuriku[1];
hokuriku1[1] = hokuriku1[0]; // hokuriku[0]: "toyama" になった
hokuriku1[0] = tmp; // hokuriku[1]: "ishiwaka" になった
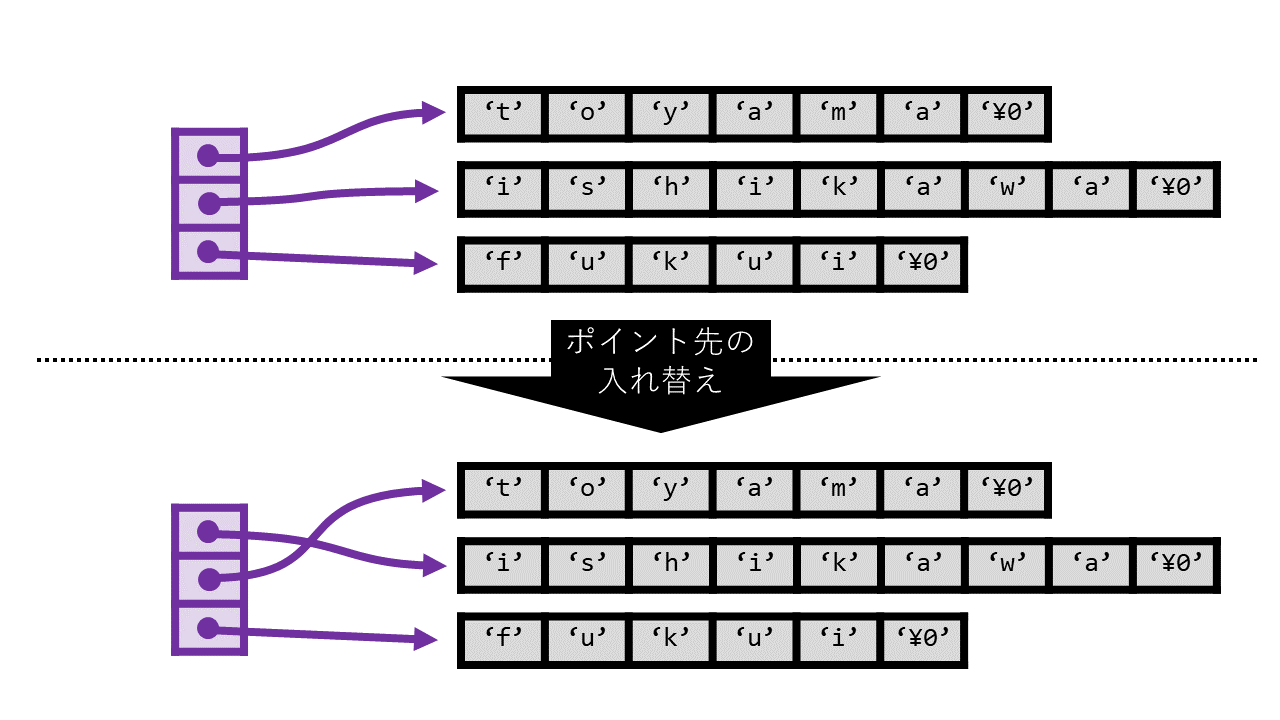
ここでは、右側の文字列たちには変更が加わっていないことに注意してください。 あくまでポインタ配列の中の値(アドレス)だけが更新されています。ポインタ配列は、特に、ソフト2でmallocを習う際に必須になります。
ポインタ配列を引数にもつ関数¶
さて、上記のhokuriku1のようなポインタ配列を引数にもつ関数はどうすれば作れるでしょうか?
ここでは、通常の配列 int a[]を引数に持つ関数はvoid f(int a[]) {...}とそのまま書けたことを思い出しましょう。
ポインタ配列はあくまで普通の配列です。その要素がポインタというだけです。なので、通常の配列と同様に、そのまま書けます。
void print_each(char *prefectures[], int n) {
for (int i = 0; i < n; ++i) {
printf("%s-ken\n", prefectures[i]);
}
}
prefecturesの中身に"-ken"を追加して表示しています。
さて、今日の最初に再確認したように、関数の引数に配列が与えられたときは、実はそれはポインタであるという点を思い出しましょう。
すなわち、関数引数中でT a[]の形が現れたときは、それは常にT *aでした。これを適用すると、上記の関数は実は次と同じです。
void print_each(char **prefectures, int n) { ... }
ここで知っておくべきことは、ポインタのポインタが出現したとき、それは様々な使い方があるということです。
- ポインタのポインタはポインタ単体を指し、そのポインタは変数単体を指す:
void find_largest2(int a[], int n, int **p_max) - ポインタのポインタはポインタ配列を指し、その要素のポインタは変数の配列(文字列)を指す:
void print_each(char **prefectures, int n)
{単体, 配列}×{単体, 配列}になっているので、残りの2パターンを考えることもできます。
- ポインタのポインタはポインタ単体を指し、そのポインタは変数の配列を指す
- ポインタのポインタはポインタ配列を指し、その要素のポインタは変数単体を指す
現実では、find_largest2のように素朴なポインタの例か、あるいはprefecturesのようにポインタ配列が文字列を指す例が多いと思いますが、
複雑なものが来ても驚かないようにしてください。
やってみよう(30分)
上記を写経してみましょう
クイズ
int *v[]をポインタで指すとすると、どういうコードになりますか?- ポインタ配列
char *prefectures[]、整数i、整数jが与えられたとき、prefectures[i]とprefectures[j]をswapする関数を書いてください。 - 上で勉強した、次のパターンの「ポインタのポインタ」の使用例を書いてください。型は
charでお願いします。- ポインタのポインタはポインタ単体を指し、そのポインタは変数の配列(すなわち文字列)を指す
- ポインタのポインタはポインタ配列を指し、その要素のポインタは変数単体(すなわちchar一個)を指す
答え
- 例えば次のようになります。 授業後訂正:重要な部分を間違えていました。アンドはいらないです。下記参照
これは、型
int arr1[] = {1, 2, 3}; int arr2[] = {4, 5}; // int *v[] = {&arr1, &arr2}; // ポインタ配列 <- 授業前には、この行を間違えていました。 int *v[] = {arr1, arr2}; // ポインタ配列 <- こちらが正しいです int **p; p = v; // ポインタのポインタで指し示す printf("v[0][1]: %d\n", p[0][1]); // v[0][1]: 2 printf("v[1][0]: %d\n", p[1][0]); // v[1][0]: 4Tに対して、T v[]を考えると、そのポインタはT *pでしたね。このTにint *を代入したと思うとわかります。 - 例えば以下。
void swap(char *prefectures[], int i, int j) { char *tmp = prefectures[i]; prefectures[i] = prefectures[j]; prefectures[j] = tmp; } int main() { char *hokuriku1[] = {"toyama", "ishikawa", "fukui"}; print_each(hokuriku1, 3); // toyama-ken, ishikawa-ken, fukui-ken swap(hokuriku1, 1, 2); // ishikawaとfukuiをswap print_each(hokuriku1, 3); // toyama-ken, fukui-ken, ishikawa-ken } - 例えば以下が「ポインタのポインタはポインタ単体を指し、そのポインタは変数の配列(文字列)を指す」例。
例えば以下が「ポインタのポインタはポインタ配列を指し、その要素のポインタは変数単体(char一個)を指す」例char *animal = "dog"; char **p; p = &animal; printf("%s\n", *p); // dogchar c1 = 'a', c2 = 'b', c3 = 'c'; char *alphabets[] = {&c1, &c2, &c3}; char **p; p = alphabets; for (int i = 0; i < 3; ++i) { printf("%c, ", *(p[i])); // a, b, c } printf("\n");
二次元配列とポインタ¶
さて、次は二次元配列のことを思い出しましょう。二次元配列は、その使用目的はポインタ配列と似ていますが、中身は違うものです。
二次元配列の基本¶
以下のような初期化表記で二次元配列を確保できましたね。
char hokuriku2[][9] = {"toyama", "ishikawa", "fukui"};
これは、先ほどの「ポインタ配列」と同じようにアクセスできます。
for (int i = 0; i < 3; ++i) {
printf("%s\n", hokuriku2[i]);
}
// toyama
// ishikawa
// fukui
二次元配列を可視化すると次のようになります。二次元配列の実際のメモリレイアウトについては既に勉強しましたね。
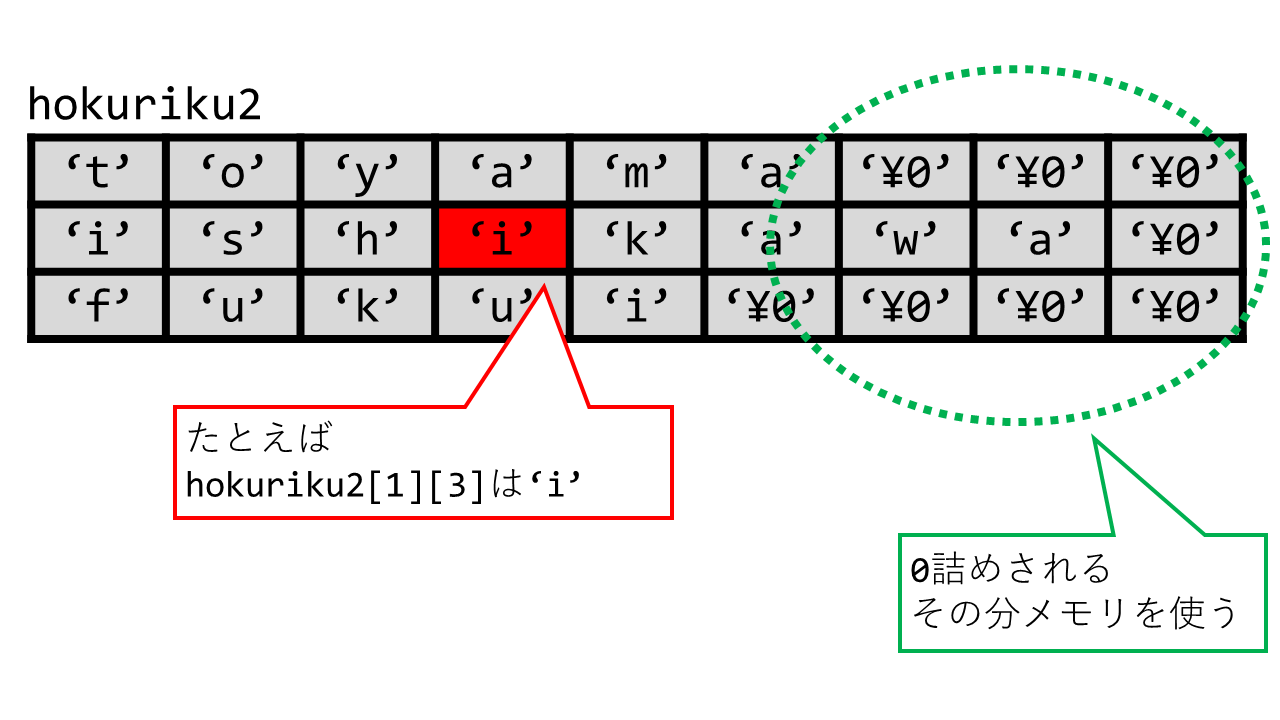
ここで、ポインタ配列hokuriku1と、二次元配列hokuriku2は、どちらも同じ情報を表現していますが違いがあります。
- 二次元配列は全ての要素が同じ長さである必要があります。すなわち、最長のものに合わせる必要があります。この場合は
ishikawaと\0の合計9個のcharを、全ての行について確保する必要があります。これは、例えばfukuiの後ろには無駄な領域を確保していることを意味します。 - 一方で、二次元配列はメモリ上では連続して確保されるため、わかりやすいという面があります。例えば
hokuriku2の場合は 3 x 9 の二重forループで全体を舐めることが出来ます。
また、二次元配列では、文字列以外も初期化記法で書けることを思い出しましょう。
int arr[][3] = {
{1, 2, 3},
{4, 5, 6}
};
二次元配列をポイントする¶
さて、「二次元配列のポインタ」はどうなるのでしょうか?ここは非常に難しいので、わからなければ、今のところは結果だけ知っておいてください。
次のような奇妙な表記になります。Reese, p104
int (*p)[3]; // 「int 3つ分」を1単位とするポインタ
p = arr; // p と p + 1 の間の値(アドレス)の差は12(つまりint3つ分)
int (*p)[3];は、「int 3つ分」を一単位とするポインタです。カッコを忘れないでください。
カッコを忘れてint *p[3]としてしまうと上で習ったポインタ配列になってしまいます。
pはポインタなので、p = arrという表記でarrの先頭アドレスを代入出来ます。
さて、「int3つ分を単位とする」とはどういうことでしょうか?普通のintポインタ(int *ip;)の場合、「int1つを単位とする」ので、
ip + 1 とipの値(アドレス)の差は4でした。ここでは、pはint3つを単位とするため、p + 1とpの値(アドレス)の差が12になっています。
さて、なぜそんな奇妙なポインタが出てくるのでしょうか?これは二次元配列の構造を考えるとわかります。
2x3の二次元配列int arr[2][3]について、arr[0]とは、要素3のint配列(の先頭アドレス)ですね。
そして、arr[1]は、次の「要素3のint配列(の先頭アドレス)」ですね。
以上より、arr[0]とarr[1]のアドレスの差は、4 * 3 = 12になることがわかります。4バイト * 三つ分です。
すなわち、&arr[0]と&arr[1]の差は12です。
さて、pがarrを指すポインタだとしましょう。ここでポインタと配列の基本ルールを思い出しましょう。
- ポインタ
pが配列arrを指しているとする p + 1、&p[1]、arr + 1、&arr[1]は全て同じものを指す。すなわち、pもarrも同じように扱える
この基本ルールにより、&arr[0]と&arr[1]の差が12である以上、pとp + 1の値(アドレス)の差も12である必要があります。
なので、arrを指すポインタは、「12バイト = int * 3」を単位とするポインタである、ということになります。
この関係を下図にまとめます。
printf("%p %p\n", &arr[0], &arr[1]); // 0x7fff571015f0 0x7fff571015fc つまり差は12
printf("%p %p\n", p, p + 1); // 0x7fff571015f0 0x7fff571015fc
ここでの結論は、
- 型
Tで幅Wの二次元配列arrへのポインタpは、T (*p)[W] = arr;と書ける - このポインタは
sizeof(T) * Wを単位とする。 Wは省略できない
ということです。
二次元配列を引数に持つ関数¶
さて、二次元配列を関数引数にとるとどうなるでしょうか?その例を以下に示します。
double avg_mat(int height, int width, int mat[][width]) {
double sum = 0.0;
for (int h = 0; h < height; ++h) {
for (int w = 0; w < width; ++w) {
sum += mat[h][w];
}
}
return sum / (height * width);
}
int main () {
int arr[][3] = {
{1, 2, 3},
{4, 5, 6}
};
printf("avg of arr: %f\n", avg_mat(2, 3, arr)); // 3.5
}
avg_matは二次元配列の要素の平均値を出すものです。ここでは以下のポイントがあります
int mat[][width]のように、一つ目の添字(高さ)は省略できるが、二つ目の添え字(幅)は省略できない- しかし、幅パラメータは同時に
int widthといった形で与えることができる(C99のVariable-Length Arrayの機能,King, p200)
コラム
C99以前では、上記を達成するためには例えば次のようにdefineなどを用いるのが普通であり、非常にめんどくさかったのです。
#define WIDTH 3
double avg_sum(int height, int mat[][WIDTH]) { ... }
さて、関数引数の配列は実はポインタであることを何度も勉強しましたね。関数引数においてint x[]はint *xであるというルールを適用すると、上記の関数は次と同じです。
double avg_mat(int height, int width, int (*mat)[width]) { ... }
sizeof(int) * width」を単位としたポインタが登場しました。
ここでは二次元配列をポインタで受け取っているということなので、まさにその通りになりましたね。
さて、二次元配列をそのまま扱うのではなく、一旦それをほぐし、単純な一次元配列だと解釈して処理することもできます。
double avg_mat2(int *mat, int num_element) {
double sum = 0.0;
for (int i = 0; i < num_element; ++i) {
sum += mat[i];
}
return sum / num_element;
}
avg_mat2は処理の結果はavg_matと同じですが、データの与え方が単純なintポインタになっています。
そして、総合計要素分だけ値をスキャンして、平均を計算します。
二次元配列はメモリ上では単なる一次元配列になっていることを思い出すと、その先頭アドレスを与えることで、次のように書けます。
printf("%f\n", avg_mat2(&arr[0][0], 2 * 3)); // OK
printf("%f\n", avg_mat2(arr[0], 2 * 3)); // OK
&arr[0][0]は二次元配列の先頭アドレスです。
vについて、&v[3]のような「添え字アクセス+&」はv + 3のような「変数名+オフセット」と同じ、というルールを適用することで、
arr[0]は&arr[0][0]と同じです。なので、それを与えてもOKです。授業後追記:より正確に書いておきます。ここで、&arr[0][0]がOKなことはわかると思います。ではarr[0]はなぜOKなのでしょうか?
ここで、任意の配列vについて、&v[3]のような「添え字アクセス+&」はv + 3のような「変数名+オフセット」と同じ、というルールを思い出しましょう。
これを適用することで、&arr[0][0]はarr[0] + 0と同じです。これの型は、int *です。0を足す部分は消すことで、arr[0]を与えてもOKです。
(ちなみに、ややこしいのですが、arr[0]は配列そのものなので、型はint [3]になります。int [3]は、int *に与えることができます。これは下記のチートシートを
参照してください。)
別の説明:arr[0]は一次元配列そのものです。なのでその型はint[3]です。よって、int *matはintへのポインタなので、先週習った通り、一次元配列の配列名を直接渡すことができます
二次元配列とポインタのチートシート¶
授業後追記:このチートシートは講義の後に追加しました 二次元配列の型は複雑なので、以下のようにまとめました。
以下をmain.cppとして保存し、コンパイルすると、手元で実行出来ます。
型情報は例えばデバッガを使えば逐一調べられますが、今回は明示的にプリントすることでまとめました。
#include <typeinfo>
#include <stdio.h>
// 一次元配列と二次元配列について、型の詳細。
// typeinfoというc++の機能を使えば、以下のように型を表示できる。
// typeid(変数).name() で型が表示される。
// そのままだと見にくいので、c++filtというコマンドで見やすく出来る
//
// How to run:
// (1) コンパイル。gccではなくてg++なので注意。つまりこれはcではなくc++プログラム
// $ g++ main.cpp
// (2) 実行。パイプでc++filtというプログラムに渡すと、見やすくなる。
// (ただし、文字列置換を行うので、普通のprintfの出力がおかしくなるかもしれないので注意)
// $ ./a.out | c++filt -t
int main(int argc, char *argv[]) {
// =================== 一次元配列の場合 ===================
int a[] = {1, 2, 3};
int *p;
p = a;
// 次のように、配列の型は「int [3]」、int型へのポインタは「int*」となる
printf("=== 0 ===\n");
printf("%s\n", typeid(a).name()); // int [3]
printf("%s\n", typeid(p).name()); // int*
// 配列とポインタは同じように扱えると習ったが、それでも、
// int [3] と int*は型が違うじゃないかと思うかもしれない。
// これはルールなので仕方ないのだが、一つの説明として、
// a + 0 を考えてみる。 a + 0 の型は実はポインタと同じ int* である。
// a + 0 も a も似たようなものだと考えると、この事実から、
// 配列をポインタと同じように扱えることがわかるかもしれない。
// 配列が関数に渡されるときは、こっちになっていると思えばOK。
// 逆に、複雑な配列に対してそれをポイントする型がわからないときは、
// "+0"して型を調べてみるといいかもしれない。
printf("%s\n", typeid(a + 0).name()); // int*
// 「a」だけの場合、それは実体としての配列(intを3つ分確保)を指している。
// sizeofも12になる。 一方、「a + 0」とした場合、
// それをポインタだとコンパイラは解釈する。sizeofも8になる。
// この二つはポインタを経由して扱う場合は同じもの。なので、
// int *p = aと出来る。
// 結論として、型が「int [3]」のものは、「int*」でポイント出来る。
printf("%p %p\n", a, a + 0); // 値は同じ。 0x7ffd864060b4 0x7ffd864060b4
printf("%lu\n", sizeof(a)); // sizeofは違う:12
printf("%lu\n", sizeof(a + 0)); // sizeofは違う:8
// 「a + 1」のように指定すると、「p + 1」と全く同じにふるまう
printf("=== 1 ===\n");
printf("%s\n", typeid(a + 1).name()); // int*
printf("%s\n", typeid(p + 1).name()); // int*
printf("%s\n", typeid(*(a + 1)).name()); // int
printf("%s\n", typeid(*(p + 1)).name()); // int
// *(a + i) とa[i]は同じ
printf("=== 2 ===\n");
printf("%s\n", typeid(&a[1]).name()); // int* ちなみにこれは &(a[1])のこと
printf("%s\n", typeid(&p[1]).name()); // int*
printf("%s\n", typeid(a[1]).name()); // int
printf("%s\n", typeid(p[1]).name()); // int
printf("=== 3 ===\n");
// &aと&pは型も値も違う(week 4を参照)
// &aは何かを考えることは難しい。結論はint (*)[3] である。
// すなわち、「int 3つ」を単位とするポインタである。
// それはなぜだろうか?例えば変数一つの場合を考える。
// int n;
// int *p;
// p = &n;
// このように、「int 1つ」であるnのアドレス(&n)を代入すべきポインタは、
// int *である。すなわち、「int 1つ」を単位とするポインタである。
// この議論を拡張し、int a[3]; とすると、
// 「int 3つ」であるaのアドレス(&a)を代入すべきポインタは、
// int (*)[3] すなわち、「int 3つ」を単位とするポインタである、と言える
printf("%s\n", typeid(&a).name()); // int (*)[3]
// &pは単純にポインタのさらにアドレスなので、ポインタのポインタ
printf("%s\n", typeid(&p).name()); // int**
// &aはaと同じ。&pはポインタ変数そのもののアドレス
printf("%p %p\n", &a, &p); // 違う: 0x7ffd864060b4 0x7ffd86406098
// =================== 二次元配列の場合 ===================
int arr[][3] = {{1, 2, 3}, {4, 5, 6}};
int (*p2)[3];
p2 = arr; // p2はarrを二次元配列として指すポインタ。
// 授業で習った通り、arrは二次元配列 int [2][3] で、
// p2は「int 3つ分を単位とするポインタ」
// では、int [2][3] を指すポインタが int (*)[3]だと
// どうすればわかるだろうか?
printf("=== 4 ===\n");
printf("%s\n", typeid(arr).name()); // int [2][3]
printf("%s\n", typeid(p2).name()); // int (*)[3]
// 一次元配列の例で見た通り、0を足すと、コンパイラは
// arrをポインタとして解釈する。そのときの型を見ると、
// それは、arrをポインタとして指すときの型。
// なので、この場合、p2と型が同じなので、OKということになる。
printf("%s\n", typeid(arr + 0).name()); // int (*)[3]
// 添え字を使って各行にアクセスする場合。これは一次元配列そのものになる
printf("=== 5 ===\n");
printf("%s\n", typeid(arr[0]).name()); // int [3]
printf("%s\n", typeid(p2[0]).name()); // int [3]
printf("%s\n", typeid(arr[0] + 0).name()); // int*
printf("%s\n", typeid(p2[0] + 0).name()); // int*
// arrやp2に&をすると次のようになる。値も異なる。
printf("=== 6 ===\n");
printf("%s\n", typeid(&arr).name()); // int (*)[2][3]
printf("%s\n", typeid(&p2).name()); // (**)[3]
printf("=== 7 ===\n");
// 以下は全てアドレスの値は同じだが、型は異なる
// 0x7ffcc93804a0 0x7ffcc93804a0 0x7ffcc93804a0 0x7ffcc93804a0 0x7ffcc93804a0
printf("%p %p %p %p %p\n", &arr, arr, &arr[0], arr[0], &arr[0][0]);
// &arrは、二次元配列そのものを一単位として扱う。よって、
// 「intが2 * 3個」を一つの単位とする。
// これは一次元配列名に&をしたときと同じ。難しいが、普段は使わない
printf("%s\n", typeid(&arr).name()); // int (*)[2][3]
// arrは二次元配列そのもの。これはそのまんま。
printf("%s\n", typeid(arr).name()); // int [2][3]
// 再度の注意として、arrに0を足すと、これをポインタとして解釈してくれる
printf("%s\n", typeid(arr + 0).name()); // int (*)[3]
// arr[0]は一行目の一次元配列そのもの
printf("%s\n", typeid(arr[0]).name()); // int [3]
// 再度の注意として、arr[0]に0を足すと、これをポインタとして解釈してくれる
printf("%s\n", typeid(arr[0] + 0).name()); // int*
// &arr[0]は難しい。考え方として、次の二通りがあると思う
// (1) &arr[0](アンド+添え字アクセス)は arr + 0(変数名+オフセット)と同じ
// というルールを適用すると、上のarr + 0になる、と覚える
// (2) arr[0]は一次元配列そのものだった。一次元配列そのものに&をつけると、
// 配列長を単位とするポインタになったことを思い出す
// (上のほうの === 3 === のところを参照)
printf("%s\n", typeid(&arr[0]).name()); // int (*)[3]
// arr[0][0]はintなので、そのポインタ。
printf("%s\n", typeid(&arr[0][0]).name()); // int*
// =================== 三次元配列の場合も同様 ===================
int arr2[2][3][4] = {
{{ 1, 2, 3, 4}, { 5, 6, 7, 8}, { 9, 10, 11, 12}},
{{13, 14, 15, 16}, {17, 18, 19, 20}, {21, 22, 23, 24}}
};
int (*p3)[3][4];
p3 = arr2; // p3はarr2を三次元配列として指すポインタ。
printf("=== 8 ===\n");
printf("%s\n", typeid(arr2).name()); // int [2][3][4]
printf("%s\n", typeid(p3).name()); // int (*)[3][4]
printf("%s\n", typeid(arr2 + 0).name()); // int (*)[3][4]
return 0;
}
やってみよう(20分)
- 上記を写経してみましょう
double avg_mat(int mat[][width], int height, int width) { ... }のように書くとエラーになります。これはwidthを宣言する前にmat中でwidthを使ってしまっているからです。これを実際に確認してみてください。
クイズ
ポインタ配列のクイズでswapを書きました。この二次元配列版を書いてみましょう。
答え
例えば以下。配列ポインタ版に比べ、多次元配列版では幅の情報(max_len)を追加で入力する必要があります。また、ポインタのコピーといったことも出来ないので、下では愚直に一文字ずつスワップしています。
void swap2(int max_len, char prefectures[][max_len], int i, int j) {
for (int len = 0; len < max_len; ++len) {
char tmp = prefectures[i][len];
prefectures[i][len] = prefectures[j][len];
prefectures[j][len] = tmp;
}
}
int main () {
char hokuriku2[][9] = {"toyama", "ishikawa", "fukui"};
swap2(9, hokuriku2, 1, 2); // "toyama", "fukui", "ishikawa"
}
コマンドライン引数¶
さて、次はコマンドライン引数について見ていきましょう。
コマンドライン引数の基本¶
コマンドライン引数とは、プログラムを実行するときに追加で与える情報です。例えば次を考えましょう。
#include <stdio.h>
int main (int argc, char *argv[]) {
return 0;
}
main関数の引数として次の二つを与えています
int argc: コマンドライン引数の個数char *argv[]:コマンドライン引数の内容を表すポインタ配列
これをコンパイルして次のように実行したとします。
$ ./a.out hoge 123
argcおよびargvには次のようにコマンドライン引数情報が入ります。
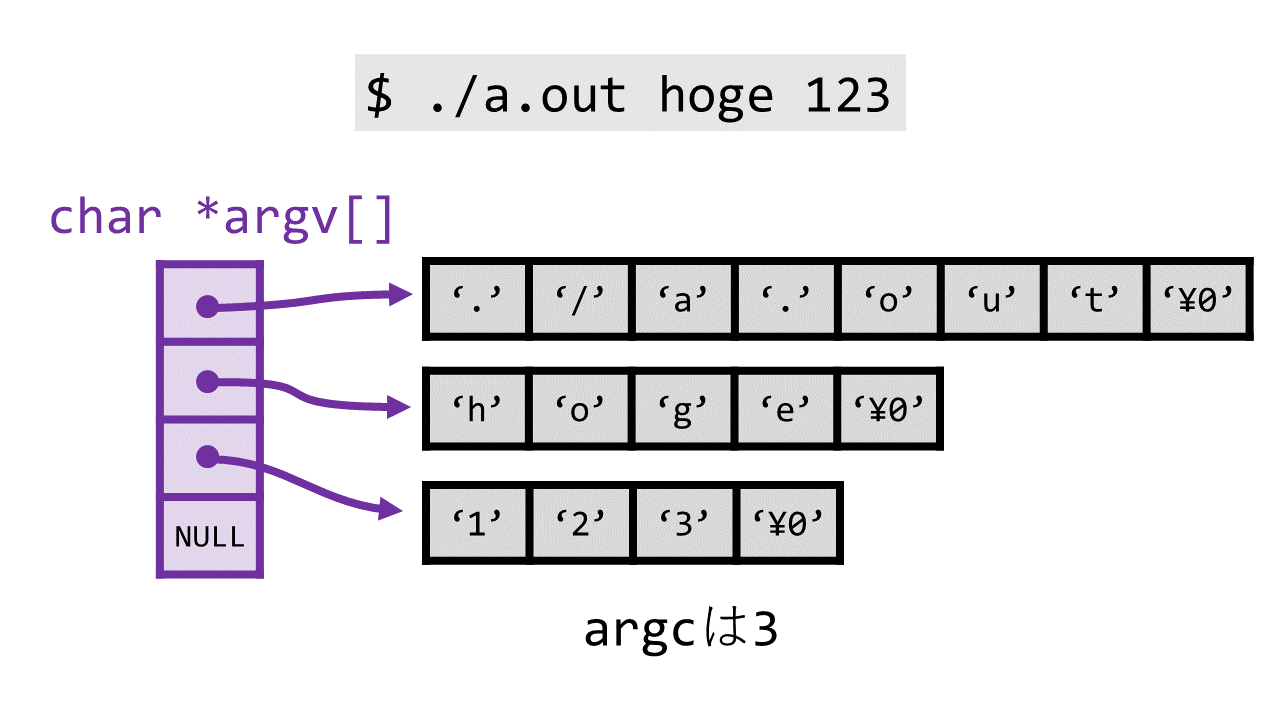
すなわち、argvの各要素には引数が入り、その個数がargcで与えられます。
例えばargv[1]とすると、それは"hoge"を意味します。
ルールとして、argv[0]にはプログラム名そのものが入ります。
また、argvの最後の要素はNULLになっていると決まっています。
このargcとargvを使うと、プログラムに対して簡単に情報を入力することができます。
コラム
argc, argvの変数名は実は任意です。以下でも大丈夫です
int main (int kosuu, char *hikisuu[]) { ... }
また、これまでに習った通り、関数引数では*argv[]は**argvと同じなので、以下のようにも書けます。
int main (int argc, char **argv) { ... }
argvをポインタ配列にするか、ポインタのポインタにするかは、好みです。
コマンドライン引数を使う例¶
それでは例を見てみましょう。まず、入力をそのまま出力する、echoコマンドを思い出しましょう。
$ echo hoge 123
hoge 123
myechoを作ってみましょう。
以下をmyecho.cとします。
#include <stdio.h>
int main(int argc, char *argv[]) {
for (int i = 1; i < argc; ++i) {
printf("%s ", argv[i]);
}
printf("\n");
}
myechoという名前でコンパイルします
$ gcc myecho.c -o myecho
$ ./myecho hoge 123
hoge 123
argv[0]は必ずプログラム名なので、それはプリントしていません。 授業後更新:上記、タイポがありました。./myechoのように、最初にドットとスラッシュがいります
また、足し算の例も見てみましょう。次をsum.cとして保存します。
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
int nums[argc - 1];
for (int i = 1; i < argc; ++i) {
nums[i - 1] = atoi(argv[i]);
}
int sum = 0;
for (int i = 0; i < argc - 1; ++i) {
sum += nums[i];
}
printf("%d\n", sum);
}
atoiはstdlib.hで定義されている便利関数で、文字列が整数と解釈出来る場合は整数として読み込んでくれます。
これをコンパイルすると、次のように使えます。
$ ./sum 12 23 34
69
atoiでおかしくなるので注意してください。そのほかに、少数を読み取ってくれるatofなどもあります。
やってみよう(20分)
上記を写経してみましょう。
クイズ
コマンドライン引数の中に"toyama", "ishikawa", "fukui"のどれかが含まれていたら、"hokuriku!"出力するプログラムを書いてください。仮に引数中にたくさん北陸の県が含まれていても、一回だけ"hokuriku!"と言うようにしてください。この際、文字列の一致を判定するstrcmpは使ってもOKです(string.hをincludeする必要があります)
答え
例えば以下です。
#include <stdio.h>
#include <string.h>
int is_hokuriku(const char *prefecture) {
char *hokuriku[] = {"toyama", "ishikawa", "fukui"};
for (int i = 0; i < 3; ++i) {
if (strcmp(prefecture, hokuriku[i]) == 0) {
return 1;
}
}
return 0;
}
int main(int argc, char *argv[]) {
for (int i = 1; i < argc; ++i) {
if (is_hokuriku(argv[i])) {
printf("hokuriku!\n");
return 0;
}
}
return 0;
}
$ a.out aichi shizuoka hokkaido
$ a.out nagano ishikawa
hokuriku!
$ a.out fukui ishikawa
hokuriku!
宿題¶
今日の宿題を今晩か明日に出します。slackでリンクを共有します。 来週までに解いてください。 宿題の締切は次の授業の前日の深夜23:59までです。(今回の場合、2020/11/4 23:59まで)。