Week 4 (2021/10/28)¶
今日やること
- ポインタの基本
- ポインタと関数
- ポインタと配列
- ポインタと文字列
まずはじめに¶
- 自動採点の結果はしっかり見てください。一文字でもずれていると自動採点をパスしません。その場合、減点になります。
ポインタの基本¶
今日はついにポインタの日です。ポインタは、これまでにちょくちょく出てきた「アドレス」に関する処理を行う概念です。 C言語における最も重要で最も難しい概念だと言えます。ポインタを用いることで、データの移動や編集が自由自在に出来るようになります。 ソフトウェア1の目的はポインタを理解することです。 ポインタを理解することは簡単ではないですが、今日一日かけて頑張って学びましょう。
ポインタとは¶
int a = 10;
int *p; // pはintへのポインタ
p = &a; // aのアドレスをpに代入
ここで、int *pという表記は、pはintへのポインタであることを意味します。
ポインタは他の変数のアドレスを内容とする変数です。
この関係を図示すると以下のようになります。
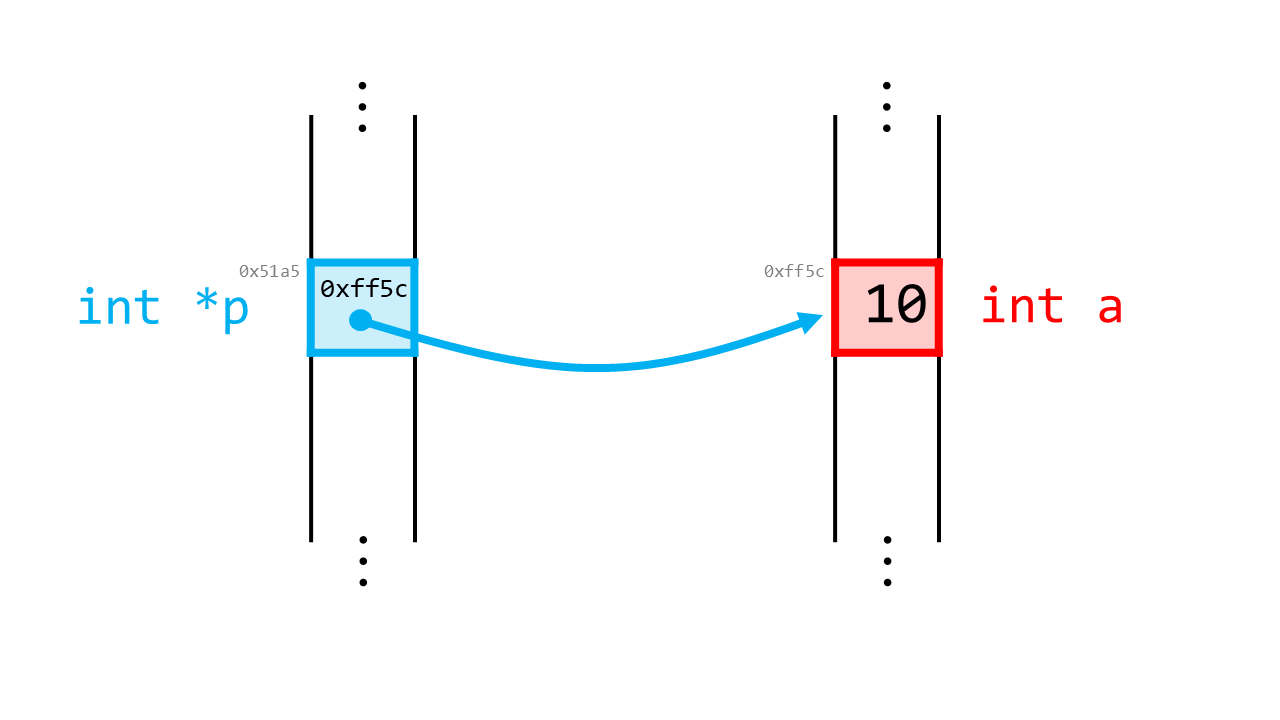
ポインタは、これまでに習った普通の変数と同様に、メモリ中にある領域(64ビットマシンの場合は64ビット)を確保します。
そして、この場合ではint型の変数aのアドレス&a(ここでは人工的な例として0xff5c)を値として持ちます。
これを、ポインタpはaを指しているとか、ポイントしているという風に表現します。
これを図中では矢印で表現しています。
ポインタの実体は、上の図で全てです。なので、ポインタについてわからなくなったら、上の図に立ち返ってみるといいです。
そして、ポインタには、 *をつけると、指している変数の値にアクセスできるという特殊能力があります。 アスタリスクなので「値(あたい)」と覚える人もいます。
printf("*p: %d\n", *p); // *p: 10
*pは指し示しているaそのものです。なので、値を表示するだけでなく、更新することもできます。
*p = 5;
printf("a: %d\n", a); // a: 5
*p += 3;
printf("a: %d\n", a); // a: 8
さて、ここで、以下のように「ポインタの値」と、「指し示している変数のアドレス」を直接表示してみましょう。 上の図で示している通り、この二つは同じものになります
// ポインタの値(&をつけていないことに注意) と、指し示しているaのアドレスは、同じです(値は人工的なものです)
printf("p: %p, &a: %p\n", p, &a); // p: 0xff5c, &a: 0xff5c
printf("&p: %p\n", &p); // &p: 0x51a5
ここでの要点は、
- ポインタは、これまでの変数と同様に、メモリ上に領域が確保されるというもの。ポインタのことを「ポインタ変数」とも言う
- ポインタは、その要素として、「指し示している対象のアドレス」を持つ
- ポインタは、「
*」をつけることで、「指し示している対象の要素」にアクセスできる
ということです。ちなみに、他の型に対するポインタも同様に作れます
double *dp; // doubleに対するポインタ
double d = 3.0;
dp = &d; // OK.
int aa = 3;
// ここで dp = &aa; のように、型が違う変数を指してはダメ。
コラム
int *a; // (int *) という型のポインタ変数a
int* a; // (int*) という型のポインタ変数a
しかしこの表記には少し問題があります。「int*」を型だと思って、ポインタを三つ作ろうと思い以下のようにすると間違いです。
int* p1, p2, p3;
int *p1, int p2, int p3と解釈され、p2とp3は普通のintになってしまいます。
よって、表記には十分注意してください。
たとえば次の表記は、
int a, b, *p;
aとbが普通のintで、pがポインタになります。
ちなみに、変数がポインタかどうか調べるにはsizeofを使えばいいです。64bit環境では、sizeof(a)は4になり、sizeof(p)は8になります。
コラム
c言語のドはまりポイントとして、ポインタ宣言のときにアスタリスク(*)を使い、ポインタが指し示す変数にアクセスするときもアスタリスクを使うという点にあります。
この二つは全く別の操作なのですが、なぜかどちらにもアスタリスクが割り振られています。 すなわち、
int a = 10;
int *p; // (1) ポインタを作るときはアスタリスクをつけるというルール
p = &a;
printf("%d\n", *p); // (2) ポインタの特殊能力:アスタリスクをつけると指している変数の値にアクセス
*を使って実現しています。
もしC言語に絵文字を使うことができれば、次のように別のシンボルを割り振ってもOKでした。
int a = 10;
int *p; // (1) ポインタを作るときはアスタリスクを付ける
p = &a;
printf("%d\n", 🍌p); // (2) ポインタの特殊能力:バナナをつけると指している変数の値にアクセス
コラム
上の2つのコラムを理解すると、次の表記も理解できると思います。 ポインタに対し、宣言したあとに値を代入するか、宣言と同時に値を代入するかで、表記にアスタリスクがつくつかないがあり わかりにくいです:
int a = 10;
int *p;
p = &a; // pに*はついてない。普通の「変数への値の代入」なので。
int a = 10;
int *p = &a; // pに*がついている。だがこれは「ポインタを宣言するときのルール」というだけ。
int *という部分はあくまでポインタを宣言するときのルールというだけです。
int n;
n = 10;
int n = 10;
ポインタのコピー¶
さて、通常の変数はコピーをすることで値を複製することができます。 全く同様に、ポインタ変数もコピーすることができます。
int a = 10;
int *p;
p = &a; // p は aを指す
int *q; // もう一個ポインタを宣言
q = p; // q = &a と同じ意味
// ここ以降、a, *p, *q は同じ意味になる
printf("a: %d, *p: %d, *q: %d\n", a, *p, *q); // a: 10, *p: 10, *q: 10
printf("p: %p, q: %p\n", p, q); // p: 0xff5c, q: 0xff5c
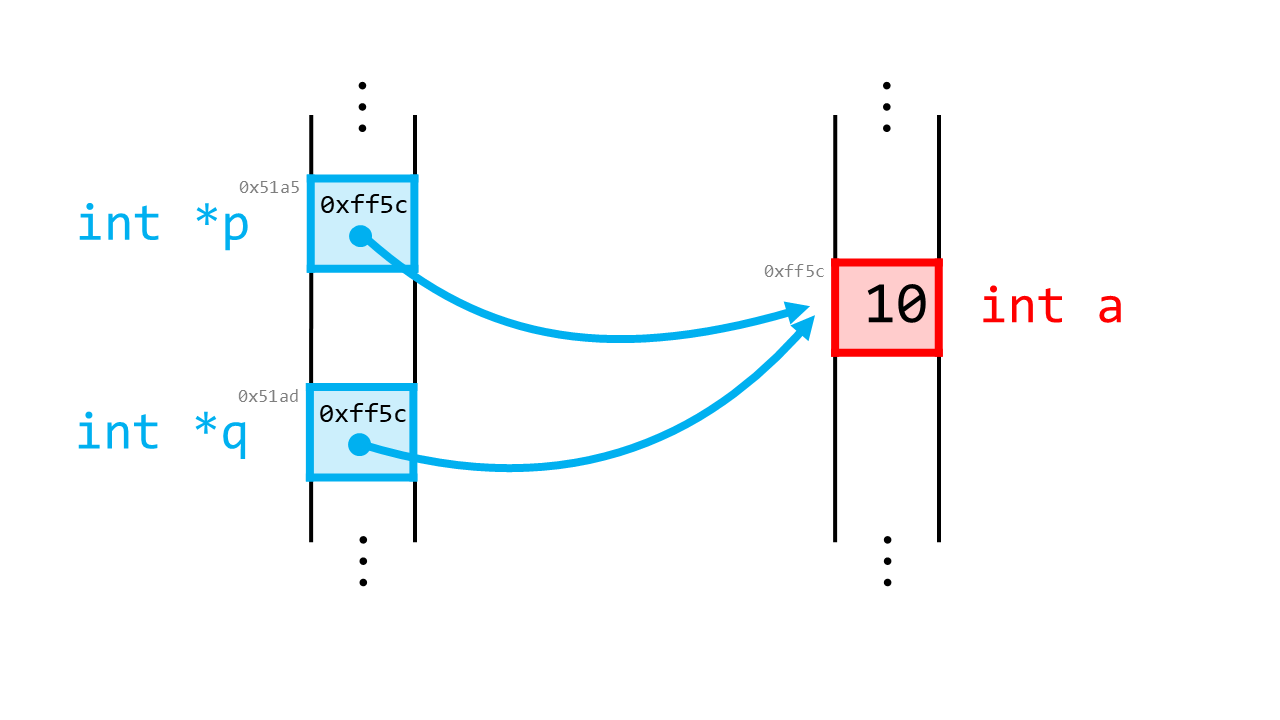
ここで、pに加えて二個目のポインタqを作ります。q = pという表記で、pの中身すなわち「aのアドレス」をqに代入します。
これは通常の変数のコピーと同じです。結果として、qもまたaを指し示すことになります。
よって、a, *p, *qはどれも同じ意味になるので、どれかを変更すれば残りの二者も変更されます。
*p = 13;
printf("a: %d, *p: %d, *q: %d\n", a, *p, *q); // a: 13, *p: 13, *q: 13
また、ポインタは単なる変数なので、別の値を指すように変更することも可能です。
int b = 3;
q = &b; // qの中身を、「bのアドレス」に変更
printf("a: %d, *p: %d, *q: %d\n", a, *p, *q); // a: 13, *p: 13, *q: 3
これを可視化すると次のようになります。qは、別の変数bを指すようになりました。
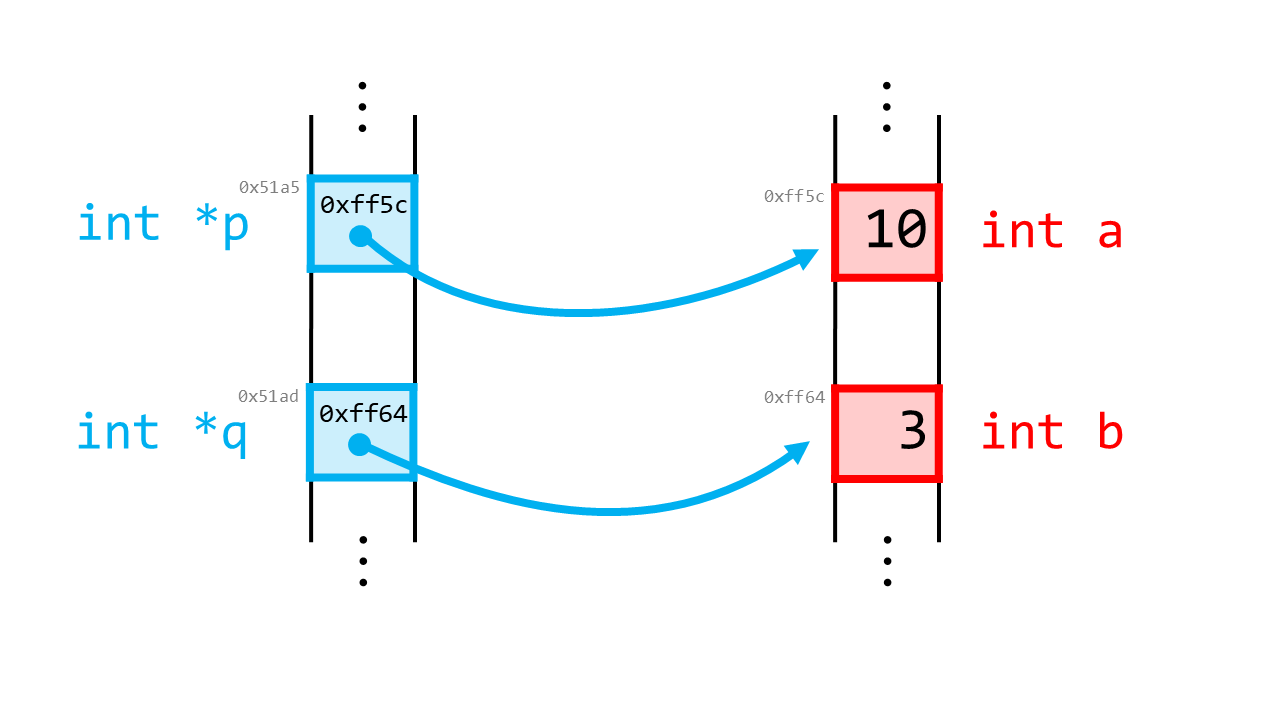
コラム
さて、p = qと*p = *qの違いを確認しておきましょう。次の例は、上で習った通り、ポインタ変数のコピーです。
int a = 10, b = 3, *p, *q;
p = &a;
q = &b;
printf("a: %d, b: %d, *p: %d, *q: %d\n", a, b, *p, *q); // a: 10, b: 3, *p: 10, *q: 3
p = q; // p = &b と同じ。ここ以降、pはaではなくbを指す(qと同じ)
printf("a: %d, b: %d, *p: %d, *q: %d\n", a, b, *p, *q); // a: 10, b: 3, *p: 3, *q: 3
*p = *qの例です。これが意味するところは、pが指している変数の値(=a)に、qが指している変数の値(=b)を代入する
という意味になります。つまり、a=bです。その後も、pはaを指しますし、qはbを指します:
int a = 10, b = 3, *p, *q;
p = &a;
q = &b;
printf("a: %d, b: %d, *p: %d, *q: %d\n", a, b, *p, *q); // a: 10, b: 3, *p: 10, *q: 3
*p = *q; // a = b と同じ。pはaを指し、a=3。qはbを指し、b=3
printf("a: %d, b: %d, *p: %d, *q: %d\n", a, b, *p, *q); // a: 3, b: 3, *p: 3, *q: 3
やってみよう(30分)
- 上記を写経してみましょう。ところどころアドレスもプリントするなどして、挙動を確実に理解しましょう。
- ポインタに対するインクリメントなども定義できます。演算子の優先順位から、後置の場合はカッコがいります。以下を試してみましょう。
int a = 10; int *p = &a; ++*p; // *p += 1 という意味。すなわち、a += 1と同じ printf("a: %d\n", a); // 11 (*p)++; // かっこがいる printf("a: %d\n", a); // 12 - ポインタを初期化しない状態で値を参照することは未定義です。おかしな結果になりますのでやってはいけません。以下を確認してみましょう
int *p; printf("%d\n", *p); // 謎の値になる。エラーになり落ちるかも。
クイズ
int a = 10;
int *p = &a;
*&a&*a*&p&*p
答え
*&a:aそのもの。まず&aはaのアドレスです。それに対して、値を取り出す*を適用しているので、これはaそのものになります。&*a: エラー。*は通常の変数には適用できないので、*aはエラーになります。*&p:pそのもの。まず&pはpのアドレスです。それに対して、値を取り出す*を適用しているので、これはpそのものになります。&*p:aのアドレス。まず*pはaになります。そのアドレスなので。
ここで、*&p, &*p, &aはプリントすると全て同じです。
printf("%p, %p, %p\n", *&p, &*p, &a); // 全部同じ
*&pはポインタ変数であるpそのものなので、別のポインタを代入できます。
int b = 0;
*&p = &b; // OK. p = &bと同じ
&*pは&aそのものであり変数ではないので、代入できません
&*p = &b; // ダメ。&a = &bと同じ。エラーになる。
ポインタと関数¶
ここまでポインタの基本を見てきましたが、ポインタは一体何の役に立つのでしょうか? それは多岐にわたると思うのですが、最も身近な例は「関数が複数の値を返したい」ときです。
関数引数¶
Cでは、関数は変数一個しかreturnすることができません。そのため、複数の値を返すときは
引数をポインタにします。
そして、呼び出し元は値を書き込みたい変数のアドレスを関数に渡すことで、その変数を編集してもらいます。
以下に例を見てみましょう King, p247
void decompose(double x, long *int_part, double *frac_part) {
*int_part = (long) x; // 少数部分の切り捨て
*frac_part = x - *int_part; // xから整数部分を引くことで小数部分の取得
}
int main() {
long n;
double d;
decompose(3.14, &n, &d);
printf("n: %ld, d: %f\n", n, d); // n: 3, d: 0.140000
}
double xを受け取って、その整数部分int_partと小数部分frac_partを返す関数decomposeを考えましょう。
ポインタを使わなければ、そのように二つの情報をreturnすることはできません。
ここでは、引数にポインタlong *int_partが登場します。呼び出し側は、値を書き込んでほしい変数long nを用意します。
そして、そのアドレス&nを、decomposeに渡します。こうすると、decompose側では
long *int_part = &n;
nを編集できるようになります。double *frac_partについても同様です。
関数の中で
*int_part = ...
nに値を書き込むことが出来ます。すなわち、以下と同じになります。
n = ...
返り値¶
さて、実は関数が「ポインタを返す」こともできます。以下の例をみてみましょう。King, p251
int *min(int *a, int *b) {
if (*a < *b) {
return a;
} else {
return b;
}
}
int main() {
int num1 = 9;
int num2 = 3;
int *ret;
ret = min(&num1, &num2);
printf("*ret: %d, ret: %p\n", *ret, ret); // *ret: 3, ret: 0x7ffdf9b0c718
printf("&num1: %p, &num2: %p\n", &num1, &num2); // &num1: 0x7ffdf9b0c710, &num2: 0x7ffdf9b0c718
}
minは、二つの整数のうち小さいほうを返す関数です。
ここでは、返り値としてポインタが設定されています。
minは、「ポインタa」の値あるいは「ポインタb」の値を返します。これは、呼び出し側から見るとnum1のアドレスあるいはnum2の
アドレスということです。それが、retというポインタに戻ってきます。
結果として、retは、num1かnum2を指す、ということになります。
この例では、retに入っている値(アドレス)は、num2のアドレスになっていますね。
ちなみにこの例は人工的な例で、ここではポインタを使わずにも同等の関数が作れます。 しかし、次に述べる「ポインタと配列」ではこの表記が重要になってきますので、しっかり理解しておいてください。
やってみよう(20分)
- 上記を写経してみましょう。
クイズ
- 与えられた配列の中から、最大値と最小値を探す次の関数を書いてみましょう。
よびだすときは次のようにします
void max_min(int a[], int n, int *max, int *min) { ... }int array[5] = {7, 2, 10, 3, 5}; int max_val, min_val; max_min(array, 5, &max_val, &min_val); printf("max: %d, min: %d\n", max_val, min_val); // max: 10, min: 2 - 上で習った
decomposeを、下のようにポインタを使わずに書くとなぜダメなのか説明してください。実際に実行して確かめてみましょう。void decompose2(double x, long int_part, double frac_part) { int_part = (long) x; // 少数部分の切り捨て frac_part = x - int_part; // xから整数部分を引くことで小数部分の取得 } int main() { long n; double d; decompose2(3.14, n, d); printf("n: %ld, d: %f\n", n, d); } - 次のように、関数内で作ったローカル変数のアドレスを返すことをしてはいけません。何故でしょうか?また、結果がどうなるか確認してみましょう。
int *f() { int b = 10; return &b; }
答え
- 例えば以下のようになります
King, p250void max_min(int a[], int n, int *max, int *min) { *max = *min = a[0]; for(int i = 0; i < n; ++i) { if (*max < a[i]) { *max = a[i]; } else if (*min > a[i]) { *min = a[i]; } } } main側から関数に引数を渡すときは「値のコピー」になります。なので、nを引数に渡すとき、渡すのはそのコピーです。関数の内側でint_partをどう編集しようが、元のnには影響しません。そのため、関数は結果をmain側に返すことが出来ません。実は、この「関数に情報を渡すときはコピーしかできない」ということは、基本的なルールです。なので、ポインタ表記にしてアドレスを渡すという処理も、「アドレスという数値をコピー」しているにすぎません。- 関数の内側で作った変数は「関数のローカル変数」であり、関数から出たときには消滅し、二度とアクセスできません。なので、そのような「消滅したもののアドレス」は無効な値です。それを
main側に戻して 再利用してはいけません。未定義の動作になります。以下のコードで検証してみましょう。ここでは、#include <stdio.h> int *f() { int b = 10; return &b; } int main() { int *a = f(); printf("*a: %d\n", *a); // Segmentation fault (core dumped) }aには関数のローカル変数のアドレスを指すというやってはいけないことをしてしまっているので、Segmentation faultというエラーになりました。ちなみに、ポインタで不正なことをするとこのSegmentation faultというエラーがよく出てきます。このエラーはやっかいですので注意しましょう。
ポインタと配列¶
次にポインタと配列について勉強しましょう。Cでは、ポインタと配列は極めて強い関係があります。 ポインタは、その値として変数のアドレスを持つことをここまで勉強してきました。全く同様に、ポインタは、配列中の要素を指すこともできます。 次の例を見てみましょう。
int a[3] = {12, 3, 5};
int *p = &a[0]; // &(a[0])のこと
int型配列aの最初の要素(a[0])のアドレスを、ポインタpに代入しています。
これにより、pはa[0]を指します。それを可視化したものが次になります。
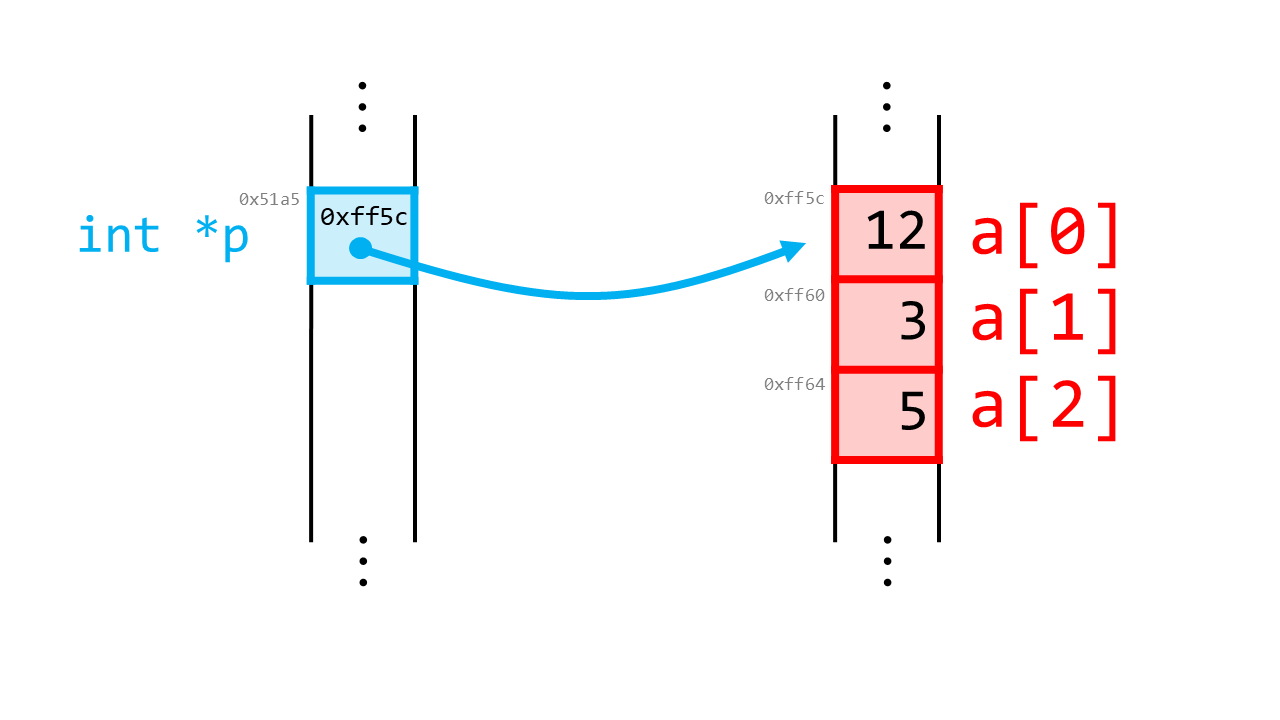 これまで同様、ポインタにアスタリスクを発動すると、指している変数の値(配列の要素)を取得することができます。
これまで同様、ポインタにアスタリスクを発動すると、指している変数の値(配列の要素)を取得することができます。
printf("%d\n", *p); // 12
*p = 2; // aは{2, 3, 5}になった
p = &a[1]とすれば、pはa[1]を指すことができます。
ポインタに対する操作¶
さて、ポインタには次のような操作が可能です。
- ポインタに対し、同じ型の他のポインタの代入(これは既に見ました)
- ポインタに対し、整数の加算と減算
- 同じ配列を指す二つのポインタの引算と比較
NULLの代入やNULLとの比較
これを見るために、次の例を考えましょう。
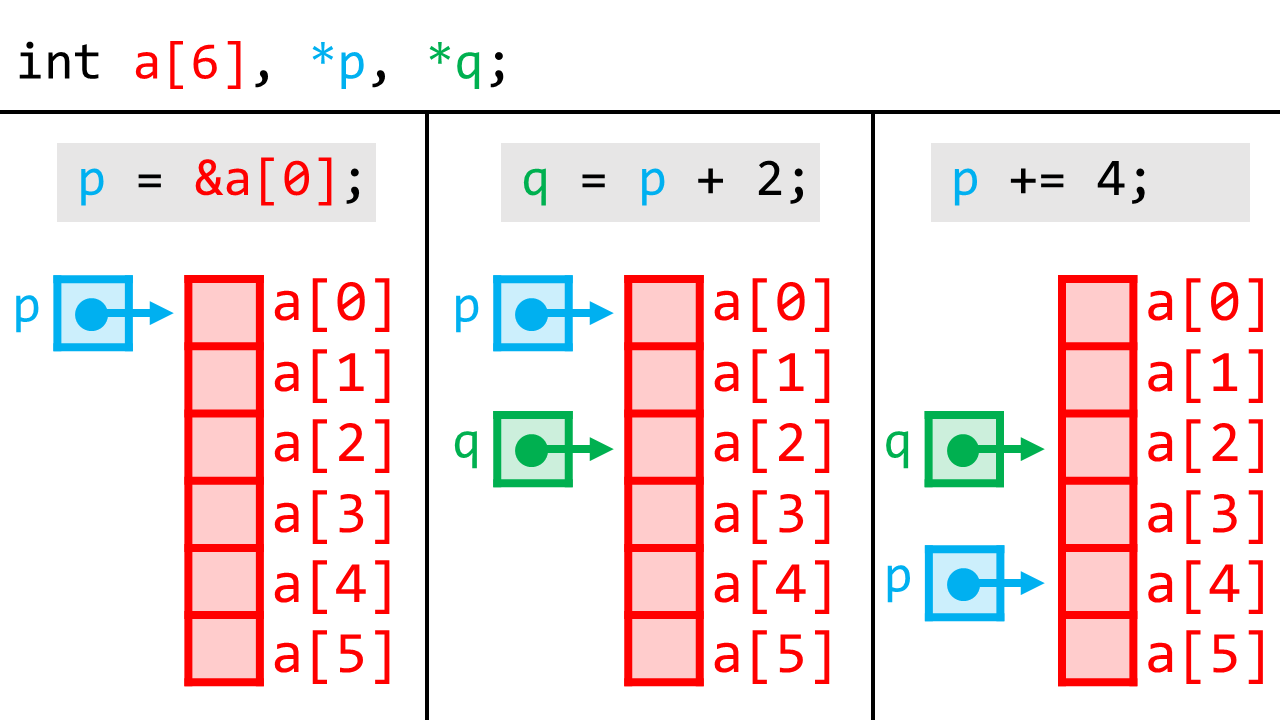
ここではまず配列とポインタ2つを作ります。
int a[10], *p, *q;
pはaの先頭を指します。
p = &a[0];
p + 2という表記は、「配列中でpが指している要素から、2つ進んだ要素」を意味します。
そして、それを別のポインタqに代入しています。
これにより、qはa[2]を指すようになります。
これを確認してみましょう。
printf("&a[0]: %p, p: %p\n", &a[0], p); // &a[0]: 0x7ffe0577ff50, p: 0x7ffe0577ff50
printf("&a[2]: %p, q: %p\n", &a[2], q); // &a[2]: 0x7ffe0577ff58, q: 0x7ffe0577ff58
pはaの先頭を指したままですね。
qはpから8バイト(=4バイトのintが2つ)分だけ
進んだ位置、すなわち&a[2]を指していることがわかりますね。
ちなみに、もし配列の要素数を超えた先にアクセスしてしまうと当然エラーになりますので、注意しましょう。
たとえばq = p + 10とすると、*qは未定義の動作になります。
また、整数加算と代入ができるので、次のような表記もできます。これにより、pはa[4]を指すようになります。
p += 4;
コラム
p + 2と書いたからといって、アドレスに2を足したものになるわけではないことに注意してください。
例えば上の例では
p:0x7ffe0577ff50p + 2:0x7ffe0577ff58(これは0x7ffe0577ff50 + 2 = 0x7ffe0577ff52ではない)
ここでは、2ではなくsizeof(int) * 2が追加されています。
より詳しく言うと、ある型Tの要素を指すポインタp, qについて、
q = p + 2と書いたとき、qにはpのアドレス + sizeof(T) * 2の分だけアドレスが加算されたものが代入されます。
ここではintなので4バイトでしたが、doubleでは8バイトです。ここは自動的に決定されますので、
ようはポインタに整数を足すとそのぶんだけ進んだ配列要素に辿り着くと覚えておいて下さい。
さて、次の例も見てみましょう。
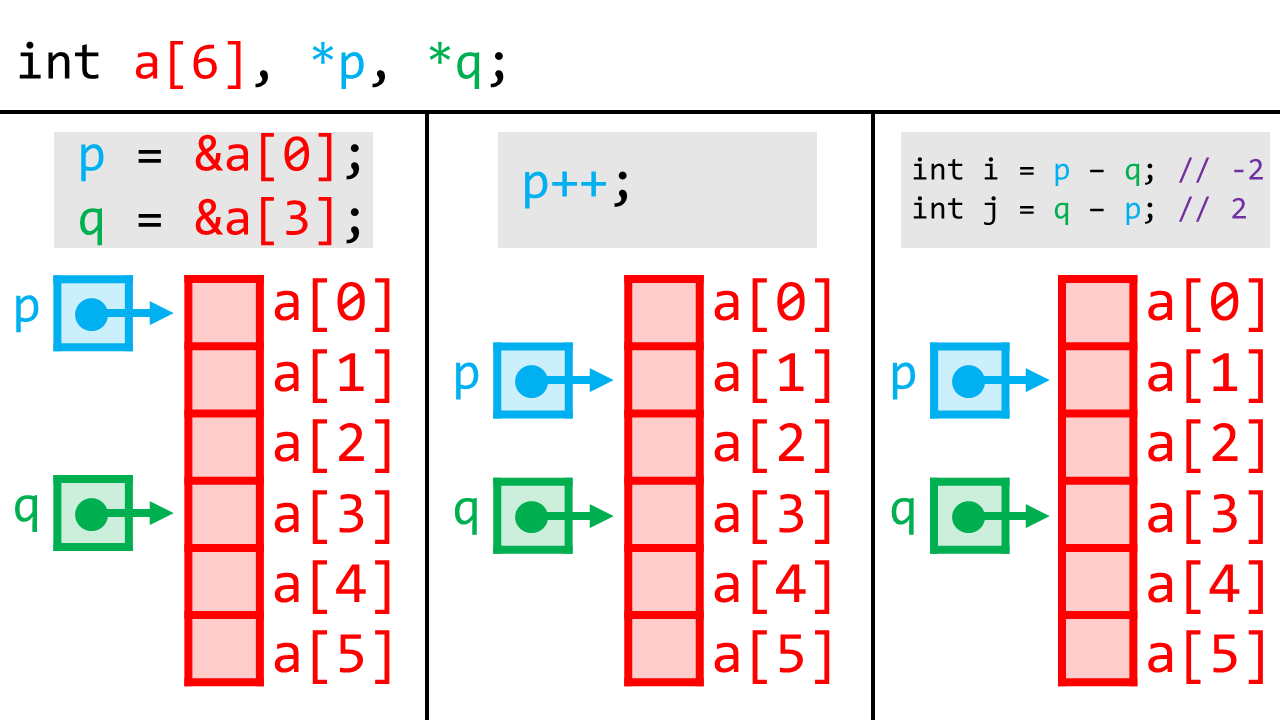 ここでは、
ここでは、
q = &a[3];
qはaの4つ目の要素を指すようになります。
また、代入と加算が出来るため、インクリメントやデクリメントも行うことができます。
p++;
pはa[0]ではなくa[1]を指すようになります。
最後に、ポインタp, qについて、その差を計算することができます。
int i = p - q; // -2
int j = q - p; // 2
pとqは同じ配列を指している必要があります。
違う配列を指している場合、結果は未定義です。
また、同じ配列を指しているポインタ同士に対して、比較や一致の判定を行うことができます。 例えば、この場合は以下のようになります
printf("p < q: %d\n", p < q); // p < q: 1
printf("p == q: %d\n", p == q); // p == q: 0
qはpより後ろを指しているので、p < qは真です。また、この二つは一致しないので、p == qは偽です。
コラム
ポインタには(1) アドレス か (2) 他のポインタ しか代入することはできませんが、唯一の例外として、
NULLを代入することができます。
int *p;
p = NULL;
printf("p: %p\n", p); // p: (nil)
NULLを代入するということは、処理の途中で、ポインタがどこも指さないことを明示的に示す、ということです。
NULLは実際はただの整数の0です。
NULLが入っているポインタに*pをしてはいけません。どこも指していないので動作は未定義です。
pがNULLかどうかの判定はif (p == NULL) { ... } のように書けますが、これは短く if (!p) { ... } とすることもできます。
ソフト1の範囲ではNULLは出てこないのですが、ソフト2でmallocという概念を習うときに出てきます。
ポインタで配列を走査¶
さて、それでは上記を踏まえてポインタで配列を走査する方式を見てみましょう。King, p261
#include <stdio.h>
#define N 5
int main () {
int a[N] = {2, 6, 1, 4, 7};
int sum1, sum2;
sum1 = sum2 = 0;
// 添え字バージョン
for (int i = 0; i < N; ++i) {
sum1 += a[i];
}
printf("sum1: %d\n", sum1); // 20
// ポインタバージョン
int *p;
for (p = &a[0]; p < &a[N]; ++p) {
sum2 += *p;
}
printf("sum2: %d\n", sum2); // 20
}
#define N 5を解説しましょう。これは、ソースコード中でNと書いた部分を、コンパイルする段階で全て5に書き換えてくれ、という意味です。
定数を定義しているようなものです。コード中にNがたくさんでてくるときに、全て5と直接書いていては、あとでそれを10に変更しようと思うと
全ての部分を変更しなければなりません。よって、上の例のようにNと書いておいて、それにdefineで値を設定する、というようなことはよくやられます。
さて、添え字バージョンを見てみましょう。これは普通に添え字iを使って配列を走査し、合計値を計算しています。
これをポインタを使って書き換えたものがポインタバージョンです。ここではポインタpを作り、
それに配列の先頭アドレスをまず設定します。これが配列の「最後の次」のアドレスに一致しない間、ループを続けます。
ループの間、*pの表記で配列要素にアクセスします。また、配列の次の要素を指すために、インクリメントを行い自身を移動させます。
このようにして、ポインタを使うことで、配列を走査することができます。
また、次のように、ポインタの宣言はforに含めることもできます。
for (int *p = &a[0]; p < &a[N]; ++p) { ... }
コラム
上記で、アレッと思いませんでしたか?というのも、配列はa[0]からa[N-1]までなので、
&a[N]という表記はいいのか?という疑問がわいてきます。実は、ここはOKです。というのも、
a[N]のように「値」にアクセスすると、配列外アクセスでダメなのですが、&a[N]という「アドレス」は、
完全に定義される(&a[N-1]にsizeof(int)を足したもの)からです。
ポインタの演算では、このように、配列の境界の直後の要素のアドレスとの比較は境界条件としてよく使われます。
配列名とポインタ¶
また、先週に少しお話した通り、配列名だけを書くとそれはその配列の先頭要素のアドレスを意味するというルールがあります。 よって、以下の表記は、配列の先頭アドレスの代入と同じになります。
p = a; // p = &a[0] と同じ
&a[3]のような配列要素のアドレスは、a + 3とも書くことができます。
これを踏まえて以下を見てみましょう。
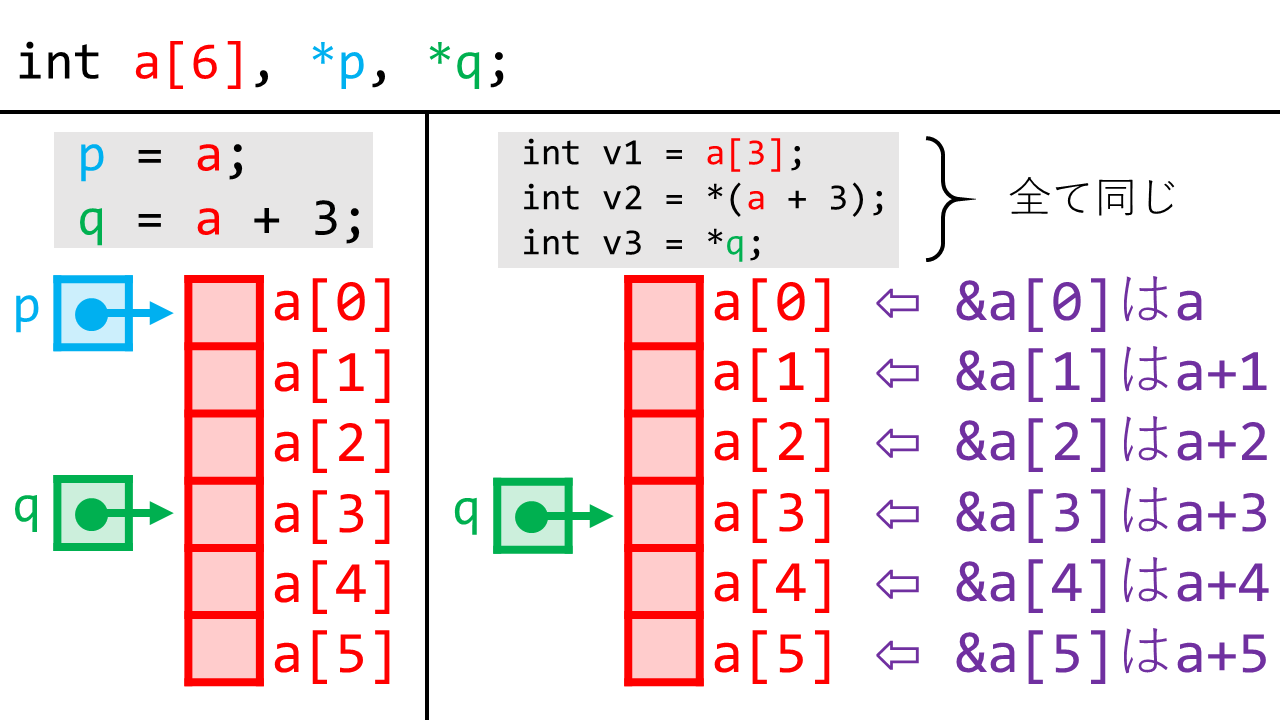
p = a, およびq = a + 3という表記で、配列中の要素を指定できています。
そして、次の3つは同じものを指します。
int v1 = a[3];
int v2 = *(a + 3);
int v3 = *q;
ここからわかるように、Cでは配列(a)とポインタ(p)はかなり似た概念になっています。
注意として、ポインタには別のポインタを代入できますが、配列のアドレスには当然できません。すなわち、以下のようになります。
int a[] = {1, 2, 3, 4, 5}, *p;
p = a;
int *r = NULL;
p = r; // 出来る(ポインタにポインタを代入)
a = r; // 出来ない(aは固定されている配列アドレスなので、別のものを代入できない)
sizeofの値も違うことを思い出しましょう。
int a[] = {1, 2, 3, 4, 5}, *p;
p = a;
printf("sizeof(p): %lu\n", sizeof(p)); // sizeof(p): 8
printf("sizeof(a): %lu\n", sizeof(a)); // sizeof(a): 20
sizeofを適用すると、ポインタ変数1つ分の大きさとして8バイト(64ビットマシンの場合)が出力されます。
一方で、配列にsizeofを適用すると、4バイトが要素数分、すなわち4 * 5 = 20バイトが出力されます。
コラム
配列a[]の要素にアクセスする際、通常の添え字アクセス(a[2])以外にも、まるでポインタのような表記(*(a + 2))が可能でした。
これは実は逆もしかりで、ポインタに対して添え字でアクセスすることもできます。
int a[] = {1, 2, 3};
int *p = a;
printf("%d, %d\n", *(p + 2), p[2]); // 3, 3
関数に配列を渡すとは¶
さて、実は、「関数に配列を渡す」とは実は「関数にポインタを渡す」ことなのです。
int sum_array (int a[], int n) {
int sum = 0;
for (int i = 0; i < n; ++i) {
sum += a[i];
}
return sum;
}
int sum_array (int *a, int n) { ... }
int a[]といった配列表記は、int *aといったポインタ表記と全く同じ意味になります。
よって、「関数に配列を渡す」ときは、配列全てをコピーするのではなく、関数の先頭アドレス一個だけをコピーします。 これは速度・メモリの消費が抑制されます。すなわち、もし超巨大な配列を関数に全てコピーしていたら、 それだけで時間がかかってしまいます。アドレス一個だけならば、配列がどんなに大きくても高速に扱うことができます。
また、ポインタである以上、実は関数内から配列要素を変更することができます。次の例を見てみましょう。
void set_one(int a[], int n) {
for(int i = 0; i < n; ++i) {
a[i] = 1;
}
}
int main() {
int a[] = {2, 3, 4};
printf("a = {%d, %d, %d}\n", a[0], a[1], a[2]); // a = {2, 3, 4}
set_one(a, 3);
printf("a = {%d, %d, %d}\n", a[0], a[1], a[2]); // a = {1, 1, 1}
}
関数引数を配列形式にするかポインタ形式にするかは状況によります。配列を入力したいということを明示的に表せ、 かつわかりやすのが配列形式です。一方、ポインタであることを強調するためにポインタ形式にすることもあります。
コラム
かなりややこしいのですが、
- 変数宣言時の
int a[]とint *aは意味が違う。配列か。ポインタか。 - 関数引数の
int a[]とint *aは同じで、どちらもint *a
というルールになっています。これはsizeofで確認できます。
// 再掲
int a[] = {1, 2, 3, 4, 5}, *p;
p = a;
printf("sizeof(p): %lu\n", sizeof(p)); // sizeof(p): 8
printf("sizeof(a): %lu\n", sizeof(a)); // sizeof(a): 20
void g1(int a[]) {
printf("sizeof(a) in g1(int a[]): %lu\n", sizeof(a)); // sizeof(a) in g1(int a[]): 8
}
void g2(int *a) {
printf("sizeof(a) in g2(int *a): %lu\n", sizeof(a)); // sizeof(a) in g2(int *a): 8
}
int main() {
int a[] = {1, 2, 3, 4, 5};
g1(a);
g2(a);
}
a[]でも*aでも、ポインタ分の8バイトになります。
このことからも、関数引数の配列表記はポインタだということがわかります。
やってみよう(30分)
- 上記を写経してみましょう。
-
上記の「配列を走査する例」は次のようにも書けます。これを眺めて、挙動を理解しましょう。
int a[N] = {2, 6, 1, 4, 7}; for (int *p = a; p < a + N; p++){ sum += *p; } -
Cの有名な謎挙動として、配列
aに対し、a[2]のことを2[a]とも書ける、というものがあります。次を実行してみましょう。ここで、コンパイラはint a[] = {1, 2, 3}; printf("%d, %d, %d, %d\n", a[2], *(a + 2), *(2 + a), 2[a]); // 3, 3, 3, 32[a]という記述を、*(2 + a)だと思って扱います。足し算は入れ替えてもいいので、これは*(a + 2)に等しいです。なので、それはa[2]に等しい、というわけです。 もちろん、このようなコードを実際に書いてはいけません。
クイズ
引数の二つの変数を入れ替えるswap関数を次のように考えます。
void swap (double a, double b) {
double tmp = a;
a = b;
b = tmp;
}
aの要素を昇順にしたいです。
double a[] = {1.0, 5.0, 3.0, 4.0, 2.0, 6.0};
- 上の
swap関数はうまくいきません。なぜか説明したうえで、うまくいくように書き換えてください。 swap関数を用いてaを昇順にしてください。その際、入力の形式を二通り書いてください。
答え
swap関数は呼び出し元の値を変更するため、ポインタにしなければならない。例えば以下
void swap (double *a, double *b) {
double tmp = *a;
*a = *b;
*b = tmp;
}
aを並べ替えるには次の二通りがある
swap(a + 1, a + 4);
swap(&a[1], &a[4]);
ポインタと文字列¶
文字列はcharの配列であることは既に勉強しました。よって、文字列に対する操作とポインタにも密接なつながりがあります。
char s[] = "hoge";
char *p = s;
printf("%c %c %c %c \n", s[2], *(s + 2), *(p + 2), p[2]); // g g g g
コラム
実際にアドレスを見てみると、p + 1としたときに、sizeof(char)すなわち1だけ値が増えていることを見ておきましょう。pをcharへの配列として、
printf("p: %p, p+1: %p\n", p, p + 1); // p: 0x7ffc75cc2413, p+1: 0x7ffc75cc2414
intのぽポインタのときは、ここはsizeof(int)すなわち4だけ増えていましたね。
このあたりは、コンパイラが自動的によしなにしてくれますので、ようは、型がなんであれ、ポインタを1増やすと配列中の次の要素に進む、と覚えておきましょう。
文字列を扱う関数の例¶
それではポインタを使って文字列を扱う関数の例をいくつか見てみましょう King, p296
int strlen1(char *s) {
int n = 0;
for(; *s != '\0'; s++) {
n++;
}
return n;
}
int main() {
char s[] = "abc";
printf("%d\n", strlen1(s)); // 3
}
strlen1関数は、文字列を受け取り、その長さを返すものです。最後にNULL文字\0が来るまでチェックを行い、
文字をカウントします。これは簡単ですね。次に、これと同じような内容を、別の書き方で書いてみます。
int strlen2(const char *s) {
int n = 0;
for (; *s; s++) {
n++;
}
return n;
}
constという記号を足しました。これは、sが指す値を変更できないという条件をsに課しています。
strlen関数は文字列sにアクセスする必要がありますが、その内容を変更する必要はありません。
ですが、char *sというポインタを渡すやり方だと、関数の内側からsを変更できてしまいます。
これは、バグの温床になりますし、関数を使う側からすると気持ち悪いです。
そのような際に、cost char *sとう表記をすると、sが指す値すなわち*sを変更することが出来なくなります。
このような表記を覚えておきましょう。
次に、strlen1であった*s != '\0'が単に*sに変更されています。
これは、NULL文字'\0'は実際はただの0という数値なので、0と違うということはたんに*sと書けるからです。
さらに次のバージョンを見てみましょう。
int strlen3(const char *s) {
const char *p = s;
while (*s) {
s++;
}
return s - p;
}
sをconst char *pで受け取っています。
ここでconstが必要なことに注意してください(でなければ、pを経由してsの指しているものを変更できてしまいます。)
そして、strlen2であったforループは上のようにwhileで書き直せます。
最後に、ループで進んだ回数が文字列長そのものなので、それはポインタの差分s - pで表現できます。
文字列の初期化¶
さて、文字列の初期化について少し見ておきましょう。以下の二通りの初期化はどちらもOKです
char amsg[] = "abc";
char *pmsg = "abc";
printf("%s %s\n", amsg, pmsg); // abc abc
char amsg[]: char型の変数を4個実際に確保。その中に'a','b','c','\0'を入れる。これらは普通の配列なので、自由にアクセス・変更できる。char *pmsg: char型ポインタを1個だけ確保。プログラムのどこかで文字列リテラル"abcd"が確保される。そのリテラルのアドレスが入る。リテラルなので、アクセスは出来るが変更は出来ない。
以下の例が違いを表しています。まず、pmsgはポインタなのでポインタやNULLを代入できますが、amsgは配列なのでそのようなことはできません。
amsg = NULL; // ダメ
pmsg = NULL; // OK
また、amsgは配列なので要素を変更出来ますが、pmsgが指しているものはリテラルなので変更できません。
amsg[0] = 'A'; // OK
pmsg[0] = 'A'; // ダメ
ここで「リテラルは変更できない」というのは、例えば整数リテラル13を考えると、この13そのものは変更できないということです。
つまり、13 = 5;のようなことはできません。同様に、"abc" = "xyz";もできません。
同様に、"abc"[0] = 'A';として"abc"を"Abc"にすることもできません。
コラム
なんで文字列リテラルを変更できないんだろう?と思うかもしれません。例えば以下の例を考えます(以下の例は環境依存ですので、プラットフォームが違うと話が変わるかもしれません。Google Cloud Shell Editorにおけるgccでは下記のようになります)
char *p = "abc";
char *q = "abc";
p, qを作った場合、それぞれに対し"abc"という領域がどこかに作られてそのアドレスが割り当てられていると考えるかもしれません。
ですが、コンパイラが賢くやってくれる場合、"abc"という領域の確保は一度だけ行われ、pとqはその同じ領域を指します(この機能のおかげで、巨大なリテラルを何度も作るような場合も、無駄なメモリ消費が起きません)
printf("%p %p\n", p, q); // 0x55e91a33b004 0x55e91a33b004 <- 同じ!
p[0] = 'x'としてpが指す内容を"xbc"とすることが出来てしまう場合、
全然別の変数であるqの中身も"xbc"になってしまい、話がおかしくなりますね。このように、文字列リテラルは編集不可能になっています。 King, p305.
やってみよう(30分)
- 上記を写経してみましょう。
クイズ
- 文字列をコピーする関数
my_strcpyを考えましょうK&R, p128。ここでは、s1がコピー先で、s2がコピー元です。以下に添え字を使ったバージョンを書きました。whileの条件式が何をしているか、考えてみましょう。 これを編集して、添え字iを使わずにポインタのインクリメントのみで計算できるよう、書き直してみましょう#include <stdio.h> void my_strcpy(char *s1, const char *s2) { int i = 0; while ((s1[i] = s2[i]) != '\0') { ++i; } } int main() { char str1[] = "aaaaaaaaaa"; char str2[] = "hoge"; printf("str1: %s\n", str1); // str1: aaaaaaaaaa my_strcpy(str1, str2); printf("str1: %s\n", str1); // str1: hoge // ここでは、str1は以下のようになっています: // {'h', 'o', 'g', 'e', '\0', 'a', 'a', 'a', 'a', 'a', '\0'} }
答え
-
whileの条件式の説明は以下です。
s1[i] = s2[i]で、コピー元のs2のi番目の要素を、コピー先のs1[i]に代入しています。つまり、どんどん上書きしています。(s1[i] = s2[i]) != '\0'ここでは、「代入式の値は、代入した値そのもの」であることを思い出しましょう。つまり、(s1[i] = s2[i])は、s2[i]そのものになります。s2[i]が終端文字の'\0'であるまで、ループを更新する、という意味になりますね。
ポインタで書き直すと、例えば以下です
これはさらに下のようにも書けます。void my_strcpy2(char *s1, const char *s2) { while ((*s1 = *s2) != 0) { s1++; s2++; } }void my_strcpy3(char *s1, const char *s2) { while (*s1++ = *s2++) { ; } }
宿題¶
それでは今週の宿題です。
- 締切は次の授業の前日の深夜23:59までです(今回の場合、2021/11/3, 23:59)
- 宿題リンクをslackで配付します。このリンクは公開しないでください。
week4_1¶
グラムシュミットの直交化法を実装しましょう。
今回扱うのは次のような設定です。\(d\)次元のベクトルが\(d\)本あるとします。これを \(\{\mathbf{v}_1, \mathbf{v}_2, \dots, \mathbf{v}_d\}\) とします。すなわち、\(\mathbf{v}_i \in \mathbb{R}^d\)です。 これらは線形独立だとします。
ここで、\(\mathrm{proj}\)という操作を次のように定義します。 $$ \mathrm{proj}_\mathbf{u}(\mathbf{v}) = \frac{\langle \mathbf{u}, \mathbf{v} \rangle}{\langle \mathbf{u}, \mathbf{u} \rangle} \mathbf{u}$$ ここで、\(\langle \mathbf{u}, \mathbf{v} \rangle\)は \(\mathbf{u}\)と\(\mathbf{v}\)の内積を表します。
このとき、グラムシュミットの直交化法とは、次のプロセスを上から順番に行っていくことで、 \(\{\mathbf{v}_1, \mathbf{v}_2, \dots, \mathbf{v}_d\}\)のベクトルたちを全てお互いに直交にするというものです。
これによりベクトルたちが直交することは、手計算をすると用意に確かめられます。
ここで\(d=2, \mathbf{v}_1 = [3, 1]^\top, \mathbf{v}_2 = [2, 2]^\top\)の例が英語版wikipediaに載っていますので、実際に確かめてみてください。
さて、これを実装してみましょう。リポジトリの中をみると、vector_set1.txtというファイルがあります。これが上記の英語版wikipediaにあった例そのものになっています。ここで、以下のようにコンパイル・実行します。
$ gcc main.c
$ ./a.out vector_set1.txt
./a.outの次に問題ファイルをおくことで、そのファイルを読み込んでくれるようになっています。この結果は以下のようになります。
0-th vec and 1-th vec: NOT orthogonal
The result is not correct. The vectors are:
0-th vec: [3.000000, 1.000000, ]
1-th vec: [2.000000, 2.000000, ]
ここで、main.cの中身を編集して、上記のグラムシュミットの直交化法を実装してください。うまくいくと、表示が以下のように変化します。
0-th vec and 1-th vec: orthogonal
これ以外にも、三次元の場合の例がvector_set2.txtおよびvector_set3.txtに入っています。vector_set1.txtが出来たら、以下のようにして2と3でもうまくいくか試してみてください。
$ ./a.out vector_set2.txt
vector_set1.txtなどを作ってください。
中間点の配分としては次のようにします。1, 2, 3に関しては自動採点がくっついています。できるところまでやってみてください。
vector_set1.txtをクリアvector_set2.txtをクリアvector_set3.txtをクリア- より大きい
dでもクリア(ボーナス。本採点ではvector_set4.txtのような大きなdのデータを用意して試します。)
ヒント
- まずは手で解いてみましょう。その処理を逐一プログラミング上で表現出来ているか確認するといいです。
- 数式では添え字は1始まりですが、プログラミングでは0始まりになっているので注意してください。
- 数式は縦ベクトルですが、プログラミングでは横ベクトルになっているので注意してください。
- 何かおかしければ常に
print_vecで確認してみましょう。 inner_productやprojといった関数を実際に作ってみて、数式と同様の処理を表現できるようにするとよいです。subtract_inplaceのような関数を作って、\(\mathbf{x} \gets \mathbf{x} - \mathbf{y}\)の処理を一行で書けるようにしておくと楽かもです。- まず二次元の場合を愚直にやってみて、三次元の場合も愚直にやってみましょう。それが出来たら、一般化しましょう。