Week 6 (2021/11/11)¶
今日やること
- 構造体
- ビット演算
- ライブラリツアー
構造体¶
今日は構造体をまず見ていきましょう。これまでは変数や配列は単一の型に関する話でした。 これに対し、様々な型の変数をまとめて一つのまとまりにしたものを構造体と呼びます。
構造体の基本¶
構造体の基本のコードを見てみましょう。ここでは二次元空間の一点を表すデータ表現を考え、それを構造体で表します。
#include <stdio.h>
struct point {
int x;
int y;
};
int main () {
struct point pt;
pt.x = 10;
pt.y = 30;
printf("%d %d\n", pt.x, pt.y); // 10 30
}
struct pointという書き方で、新たに構造体を宣言できます。
ここでpointという部分は構造体タグと呼ばれます。構造体タグは構造体の名前です。
構造体の中で命名された変数はメンバと呼ばれます。
ここではint xとint yをメンバとして持ちます。
この宣言の部分はあくまで宣言だけなので、メモリを使いません。
構造体は、struct point ptといった表記で、一つ生成することができます。
ここでは、
新たな型 struct pointの変数ptを一個作る、という意味です。
ptのメンバ変数は、ドットで読み書きすることができます。
コラム
このように、構造体宣言によって定義された変数がptとして作られたとき、ptのことをインスタンス(実体)と呼びます。
インスタンスは、実際にメモリを消費します。これは構造体によらない話で、型によって作られる「もの」をインスタンスと言います。
さて、いくつかの表記を勉強しましょう。 以下のように、構造体は宣言と同時にインスタンスを確保することもできます。しかし、この表記は使う機会はあまりないかもしれません。
// 以下の表記で、(1) 構造体の宣言と(2) インスタンスptの作成 を同時に行う
struct point {
int x;
int y;
} pt;
インスタンスの初期化は、初期化の演算子を使って次のようにも書けます。変数の順番は、宣言のときと同じです。
struct point pt = {10, 30};
// 上は、以下と同じ
// struct point pt;
// pt.x = 10;
// pt.y = 30;
また、C99からは次のようにメンバ変数を指定して初期化する表記が可能になりました。
struct point pt = {.x = 10, .y = 30};
struct point pt = {.y = 30, .x = 10};
次のように、初期化以外の部分では初期化構文を使えません。その場合、型名を最初にカッコで書くと 可能になります。この機能を複合リテラルと言います。
struct point pt;
// pt = {.x = 10, .y = 30}; // これはダメ
pt = (struct point){.x = 10, .y = 30}; // これはOK
いちいちstruct pointと二単語書くのがめんどくさいときは、typedefという機能をつかって、
言い換えることができます。次の例では構造体の宣言時にstruct pointをPointと言い換えています。
これにより、Pointを新たな型だと思って、Point ptのようにより直感的にインスタンスを作れます。
struct point {
int x;
int y;
};
// このようにtypedefすることで、
// 「struct point」と書く代わりに「Point」と書けるようになる
typedef struct point Point;
int main() {
// 「Point」と書ける
Point pt = {.x = 10, .y = 30};
}
また、typedefに関して、以下のようにまとめて書くこともできます。
// (1) pointの定義と(2) typedef を一つにまとめた書き方
typedef struct point {
int x;
int y;
} Point;
int main() {
// 「Point」と書ける
Point pt = {.x = 10, .y = 30};
}
コラム
typedef 旧型名 新型名 の表記により、構造体に限らず型名を新しく作ることができます。例えば
typedef int JPY; // 今後、JPYはintと同じ意味
JPY salary = 100;
printf("my salary: %d\n", salary); // 100
構造体は別の構造体に代入できます。この場合、メンバ変数は全てコピーされます。
また、==や!=を使うことはできません。
Point pt = {.x = 10, .y = 30};
Point pt2 = pt; // pt2.x = pt.x および pt2.y = pt.y が行われる
printf("%d %d\n", pt.x, pt.y); // 10 30
printf("%d %d\n", pt2.x, pt2.y); // 10 30
// 次のようなことはできない
// if (pt == pt2) { ... }
構造体の中に配列をもったり、構造体自身を持ったりすることもできます。Pointの構造体が定義されているとして、
Pointを二個、および名前をもった構造体Rectは以下のように作れます。
#define MAX_NAME_LEN 20
typedef struct rect {
Point pt1;
Point pt2;
char name[MAX_NAME_LEN + 1];
} Rect;
int main () {
Rect r = {.pt1 = {.x = 10, .y = 30},
.pt2 = {.x = 25, .y = 12},
.name = "sample_rect"};
printf("r.pt1 = %d, %d\n", r.pt1.x, r.pt1.y); // 10 30
printf("r.pt2 = %d, %d\n", r.pt2.x, r.pt2.y); // 25 12
printf("r.name = %s\n", r.name); // sample_rect
}
r.pt1.xのようにドットを連続させることで、メンバの構造体のメンバにアクセスできます。
ここで、注意として、メンバの配列はchar name[MAX_NAME_LEN + 1]のように明示的に配列の長さを決定する必要があります。
char name[] のようにしてはダメです。
コラム
ここで構造体の非常に奇妙な特性を紹介します:構造体がメンバに配列をもつとする。このとき、構造体をコピー すると、メンバ配列の中身も全てコピーされます。 まず通常の配列を思い出しましょう。配列は、単純な代入でコピーすることができません。
int arr[3] = {1, 2, 3};
int arr2[3] = arr; // ダメ
一方で、構造体はコピー可能だと上で述べました。その場合、各メンバ変数がコピーされます。 ここで、構造体が配列をもつとします。ここで構造体をコピーすると、なんと 配列の中身が全て自動でコピーされるのです。 これはポインタが関係するのではなく、全てコピーです。 なので、次の例が示すように、別の構造体にコピーしたあとは、内部の配列はそれぞれ別々です。
typedef struct a {
int arr[3];
} A;
int main () {
A a1 = {.arr = {1, 2, 3}};
A a2 = a1; // a1.arrの中身全てがa2.arrにコピーされる!
for (int i = 0; i < 3; ++i) {
printf("%d, %d\n", a1.arr[i], a2.arr[i]);
// 1, 1
// 2, 2
// 3, 3
}
a2.arr[0] = 100; // 値を編集
for (int i = 0; i < 3; ++i) {
printf("%d, %d\n", a1.arr[i], a2.arr[i]);
// 1, 100 編集がa2にだけ反映されている
// 2, 2
// 3, 3
}
}
構造体と関数¶
さて、構造体を関数で扱う方式を見てみましょう。構造体は通常の変数と同じように関数に渡すことができます。
上で述べたPointが定義されているとして、
void print_point(Point pt) {
printf("pt: (%d, %d)\n", pt.x, pt.y);
}
Poitnt pt = {.x = 10, .y = 3};
print_point(pt); // pt: (10, 3)
また、構造体を返すこともできます。次の例は、二つのPointを受け取り、x, yのそれぞれで和をとり、結果を返すものです。
Point add_point(Point pt1, Point pt2) {
pt1.x += pt2.x;
pt1.y += pt2.y;
return pt1;
}
Point pt_a = {.x = 10, .y = 2};
Point pt_b = {.x = 3, .y = 5};
Point out = add_point(pt_a, pt_b);
print_point(pt_a); // pt: (10, 2)
print_point(pt_b); // pt: (3, 5)
print_point(out); // pt: (13, 7)
print_point(pt_a); // pt: (10, 2) // pt_aは変更されない
pt1をいくら変更しても、呼び出し元のpt_aは変更されません。
この「コピーで渡す」という特性には注意が必要です。例えば巨大な配列をメンバとしても持つ
BigArrayという構造体を考えます。
そしてそれを引数として受け取るdo_nothing関数を考えます。
typedef struct big_array {
double val[1000];
} BigArray;
void do_nothing(BigArray ba) {
printf("do_nothing\n");
}
BigArray tmp;
do_nothing(tmp); // 構造体のコピー、すなわち巨大配列のコピー
returnするときも同じです。構造体が巨大である場合、それを関数内で作ってreturnすると、
大がかりなコピーが発生します。
やってみよう(20分)
上記を写経してみましょう
構造体の配列¶
構造体を要素としてもつ配列を作ることも出来ます。これはintなどの配列を作るときと同様に出来るので、わかりやすいです。
例えばPointを3つ作りたいときは次のようにします。
Point points[3];
Point points[3] = {
{.x = 3, .y = 4},
{.x = 5, .y = 6},
{.x = 7, .y = 8}
};
for (int i = 0; i < 3; ++i) {
print_point(points[i]);
}
// pt: (3, 4)
// pt: (5, 6)
// pt: (7, 8)
コラム
これまで明示的に触れませんでしたが、もともとCでは配列の長さはコンパイル時に大きさが決定される必要がありました。 ですが、C99では可変長配列(Variable-Length Array; VLA)という機能が導入され、配列の長さを変数で与えたり出来るようになりました。 例えば次のコードです。
int a[3]; // 通常の配列
int N = 3;
int b[N]; // 可変長配列
int a[3] = {1, 2, 3}; // OK
int a2[] = {1, 2, 3}; // OK。上の単なる省略表記
int N = 3;
int b[N] = {1, 2, 3}; // ダメ
そして、このことは構造体配列でも同様で、次の表記は出来ません。
int N;
Point points[N] = { // ダメ。可変長配列なので初期化表記を使えない
{.x = 3, .y = 4},
{.x = 5, .y = 6},
{.x = 7, .y = 8}
};
構造体とポインタ¶
さて、構造体へのポインタも、通常の変数のポインタと同様に扱うことができます。
Point pt = {.x = 3, .y = 10};
Point *q;
q = &pt; // q はPoint型変数ptへのポインタ
(*q).xのようにします。カッコが必要なことに注意してください。
*q.xだと*(q.x)の意味になってしまいます。この「ポインタが指す構造体のメンバ変数へのアクセス」はよく使うため、特殊な記法が
用意されており、q->xと書けます。これをまとめると次のようになります。
printf("%d\n", (*q).x); // 3. メンバへのアクセス。
printf("%d\n", q->x); // 3. 上と全く同じ処理。「->」という特殊な記法
さて、構造体はポインタをメンバ変数として持つこともできます。 その場合、構造体をコピーしたときにコピーされるのはポインタつまりアドレスなので、注意が必要です。 まず下の例を見てみましょう。
#define MAX_LEN 6
typedef struct str_by_arr {
char s[MAX_LEN + 1];
} StrByArr;
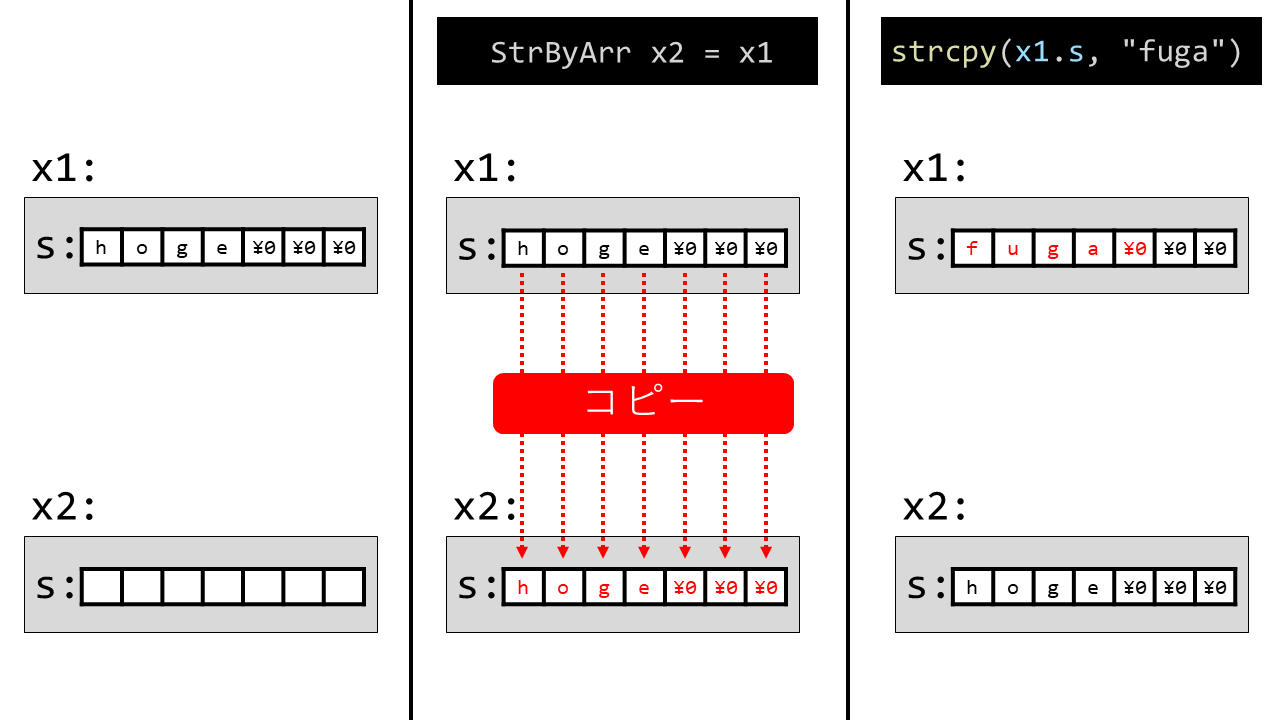
StrByArrを考えます。その実体は配列になっています。
これに対し次の処理を考えます。
StrByArr x1 = {.s = "hoge"};
StrByArr x2 = x1;
strcpy(x1.s, "fuga");
printf("x1.s: %s\n", x1.s); // x1.s: fuga
printf("x2.s: %s\n", x2.s); // x2.s: hoge
x1を作り、その内容をx2にコピーします。
先ほど勉強した通り、ここでは配列内全てのコピーが発生するということに注意しましょう。
その後、x1の中身をhogeからfugaに変更します。
ここではx1とx2は全く違うものなので、当然、x2の中身は変更されません。
これを図示すると次のようになります。
一方で、この自作string構造体を次のようにポインタで実現するとします。
typedef struct str_by_ptr {
char *s;
} StrByPtr;
buffという配列に文字列を確保し、そこを指すy1を考えます。
char buff[] = "hoge";
StrByPtr y1 = {.s = buff};
StrByPtr y2 = y1;
strcpy(buff, "fuga");
printf("y1.s: %s\n", y1.s); // y1.s: fuga
printf("y2.s: %s\n", y2.s); // y2.s: fuga
StrByArrのときと同様にy1をy2にコピーします。しかし、
このときにコピーされているのは「ポインタ変数そのもの」です。これにより、y1もy2も
同じbuffを指すようになります。そのため、もしbuffを変更してしまうと、
y1もy2も変更することになります。これを図示すると次のようになります。
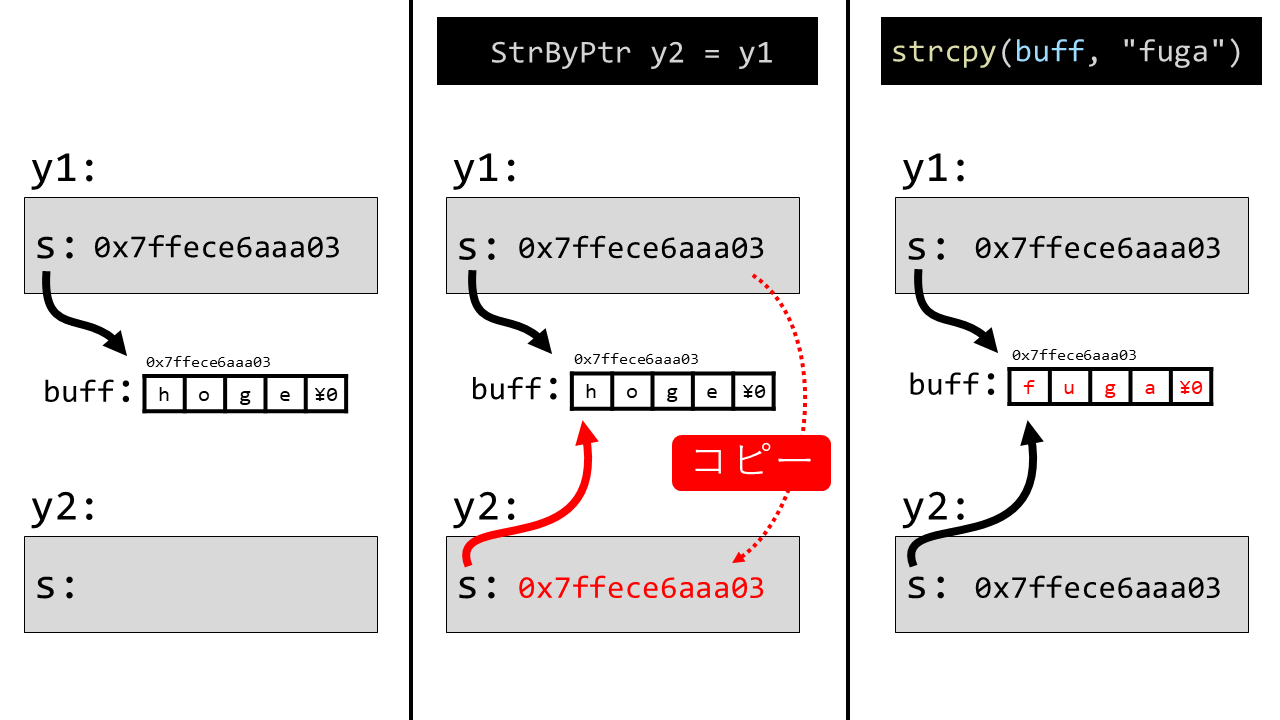
ここで実際にy1, y2のメンバのs(指し示しているアドレス)
を確認すると、同じであることがわかります。
printf("%p %p\n", y1.s, y2.s); // 0x7ffece6aaa03 0x7ffece6aaa03
やってみよう(20分)
上記を写経してみましょう
クイズ
- 上記で考えた
PointおよびRectが定義されているとし、次のコードを考えますこのとき、次の4つはそれぞれ何を意味するでしょうか?Rect r = {.pt1 = {.x = 10, .y = 30}, .pt2 = {.x = 25, .y = 12}, .name = "sample test"}; Rect *q = &r;r.pt1.x,q->pt1.x,(r.pt1).x,(q->pt1).x - 以下のように
Point ptとRect rが与えられたとき、ptがrの中に含まれれば1、そうでなければ0となるような処理を書いてください。 ここで、r.pt1は必ず左上(xもyも値が小さい)、r.pt2は必ず右下(xもyも値が大きい)とします。 例えば次の場合は含まれるので1が返ります。Rect r = {.pt1 = {1, 1}, .pt2 = {3, 4}}; Point pt = {.x = 2, .y = 2}; - 上記について、
r.pt1とr.pt2の条件が外れた、次の場合も対応してください。どちらの場合でも、結果は1になります。Rect r = {.pt1 = {3, 4}, .pt2 = {1, 1}};Rect r = {.pt1 = {1, 4}, .pt2 = {3, 1}};
答え
- 全て同じ。
10 - 例えば次
int ptinrect(Point p, Rect r) { // K&R, p158 // pがrに含まれれば1を、そうでなければ0を返す。 // rは標準形式である必要がある、 return p.x >= r.pt1.x && p.x < r.pt2.x && p.y >= r.pt1.y && p.y < r.pt2.y; } - 例えば、次のような標準形式変換関数を作る
そのうえで、次のように呼ぶ
int min(a, b) { if (a < b) { return a; } else { return b; } } int max(a, b) { if (a < b) { return b; } else { return a; } } Rect canonrect(Rect r) { // K&R, p169 // rを標準形式にして返す。標準形式とは、pt1は左上を指し、pt2は右下を指す形式 Rect tmp; tmp.pt1.x = min(r.pt1.x, r.pt2.x); tmp.pt1.y = min(r.pt1.y, r.pt2.y); tmp.pt2.x = max(r.pt1.x, r.pt2.x); tmp.pt2.y = max(r.pt1.y, r.pt2.y); return tmp; }printf("%d\n", ptinrect(pt, canonrect(r)));
ビット演算¶
さて、次はビット演算を考えましょう。プログラミングにおいて、全ての変数の
実体は0か1という数字が並んでいる列です。この0, 1に対して処理を行うことをビット演算と言います。
ビット演算はローレベルな処理です。普段のプログラミングで出会う機会は少ないかもしれませんが、速度やメモリ効率を追求するときに切っても切れないです。
ある種、C/C++らしい処理だと言えます。
また、ビット演算を知っていると、それを使わなければ書きづらいような処理を簡単に書けるときもあります。
以下では、簡単のためunsigned char (非負の8ビット整数。8桁の二進数)を考えます。
なぜunsignedなものにするかというと、signedな整数は最上位桁を負の数の表現に使うためわかりにくい場面があるからです。
基本的な演算¶
まずは準備として、unsighed charを8ビットの二進数として表示してくれる以下の関数を考えましょう。
void print_bit_uchar(unsigned char c) {
for (int i = 0; i < 8; ++i) {
if (c & 1 << (7 - i)) {
printf("1");
} else {
printf("0");
}
}
printf("\n");
}
unsigned charの変数を渡すと、その二進数表記を表示してくれます。
unsigned char a = 3;
printf("%u\n", a); // 3
print_bit_uchar(a); // 00000011
さて、ビット演算のための演算子を見ていきましょう。
unsigned char a = 3; // 00000011
unsigned char b = 6; // 00000110
unsigned char x;
// ビットごとのAND
x = a & b;
print_bit_uchar(x); // 00000010
printf("%u\n", x); // 2
// ビットごとのOR
x = a | b;
print_bit_uchar(x); // 00000111
printf("%u\n", x); // 7
// ビットごとのXOR
x = a ^ b;
print_bit_uchar(x); // 00000101
printf("%u\n", x); // 5
printfすると整数です。これを先ほどのビット表示関数に入れると、結果を2進数で可視化してくれます。
次に、ビット演算独特のシフト演算子、およびビット反転を見ていきましょう。
unsigned char a = 35; // 00100011
unsigned char x;
// 左シフト
x = a << 2; // 右側は0詰めされる
print_bit_uchar(x); // 10001100
printf("%u\n", x); // 140
// 右シフト
x = a >> 2; // unsignedの場合、左側は0詰めされる
print_bit_uchar(x); // 00001000
printf("%u\n", x); // 8
// 1の補数(ビット反転)
x = ~a; // 単項演算子
print_bit_uchar(x); // 11011100
printf("%u\n", x); // 220
また、「&」「|」「^」「<<」「>>」は全て「=」と組み合わせて代入演算子とすることができます。
a <<= 2; // a = a << 2 の略
print_bit_uchar(a); // 10001100
printf("%u\n", a); // 140
コラム
実はgccとclangではバイナリ定数表記が準備されています。
すなわち、先頭に0bをつけ、後ろに0, 1を並べることで、
二進数の整数を直接表記することができます。
例として、以下のaとbは全くおなじものです
unsigned char a = 12;
unsigned char b = 0b00001100;
print_bit_uchar(a); // 00001100
print_bit_uchar(b); // 00001100
やってみよう(20分)
上記を写経してみましょう
複雑な操作¶
さて、それでは上記のビット演算を組み合わせることで、様々な操作を実現していきましょうKing, p512。まずは「i番目の位置にビットをセットする」方法を学びましょう。
// 00000001 を左側にiビットずらす。つまり右からiビット目を1にする
// 注意:一番右は0ビット目
int i = 3;
unsigned char mask = 1 << i;
print_bit_uchar(mask); // 00001000
unsigned char a = 0b00000101;
a = a | mask; // aのうち、maskの位置にビットを立てる
print_bit_uchar(a); // 00001101
aに対し、右からi番目のビットを立てることができます。
これは次のようにまとめて表記できます。
a |= 1 << i; // a のうち右からiビット目を1にする
次に、「右からiビット目を0にする」方式を学びましょう。
// 右からiビット目を1にしたものを反転。つまり右からiビット目が0でそれ以外1
int i = 3;
unsigned char mask = ~(1 << i);
print_bit_uchar(mask); // 11110111
unsigned char a = 0b00001110;
a = a & mask; // aのうち、0のところは必ず0。それ以外はmaskに等しい
print_bit_uchar(a); // 00000110
aの右からi番目をクリア(0にする)ことができます。これをまとめると下記です。
a &= ~(1 << i); // a のうち右からiビット目を0にする
次に、「i番目のビットが立っているかどうかの判定」を学びましょう。
// 右からiビット目を1
int i = 3;
unsigned char mask = 1 << i;
print_bit_uchar(mask); // 00001000
unsigned char a = 0b00001110;
// aに対し、maskの位置(右からiビット目)に1がたっている場合:
// そこは1になる。それ以外は0になる(maskが0なので)
// 結局、a & mask はmaskと同じ値、すなわち非0になるので、その真偽値は真になる
if (a & mask) {
printf("a's %d-bit is on\n", i);
}
unsigned char b = 0b00000110;
// bに対し、maskの位置(右からiビット目)に1がたっていない場合:
// そこは0になる。それ以外も0になる(maskが0なので)
// 結局、b & mask は0(偽)になる
if (b & mask) {
printf("a's %d-bit is on\n", i); // ここには到達しない
}
// aの右からiビット目に1が立っている場合、という意味
if (a & 1 << i) { ... }
コラム
あらためてprint_bit_ucharを見てみましょう。
for (int i = 0; i < 8; ++i) {
if (c & 1 << (7 - i)) {
printf("1");
} else {
printf("0");
}
}
1 << (7 - i)の部分は、00000001を左に7-iビット分だけシフトさせています。
つまり、i = 0のとき10000000、i=1のとき01000000、といった具合です。
つまり、左からi番目に1が立った数を作っています。
ちなみに、演算子の優先順位としてはc & 1 << 7 - iでもよいのですが、わかりやすさのためにカッコをつけています。
これとターゲットのcのビット毎ANDをとるということは、ターゲットの整数の
左からi番目が1なのかどうか調べている、ということです。
ビット演算の例¶
さて、ここまで色々学んできましたが、果たしてビット演算というのは具体的にどういうときに使うのでしょうか? 古典的な例は、フラグの管理です。ここでは、お店の麺類メニューをどう表現するかを考えます。 以下のように、各麺類をある数字として宣言します。
#define RAMEN 0b000000001
#define SOBA 0b000000010
#define UDON 0b000000100
#define PASTA 0b000001000
さて、下記を見てみましょう。
unsigned char menu = 0;
// SOBA bitを立てる
menu |= SOBA; // 00000010
// UDON bitを立てる
menu |= UDON; // 00000110
if (menu & SOBA) {
printf("We're selling SOBA\n");
}
&演算子で簡単にチェックできます。
この表記の利点はなんでしょうか?
- メモリ効率の良さ。上記に対しラーメンを売っているときは
int ramen_flag = 1のように別々に変数を割り当てることもできるのですが、 多くのメモリ領域を使ってしまいます。これを上記のようにフラグで表現すればメモリの節約になります。 - 状態をまとめて表現。上記のようなフラグ管理は状態をまとめて一つの整数で表現出来るため、便利です。
このように、フラグ管理のためにビット演算は使われてきました。 特に、メモリ量が十分でなかった時代によく使われていたと思います。 現代ではメモリ量を切り詰める目的でフラグ管理をすることは少ないかもしれませんが、覚えておくとよいです。
さて、別の応用例も考えてみましょう。ある集合\(\mathcal{X}\)に対し、その冪集合(部分集合全てを集めた集合)\(2^\mathcal{X}\)を考えます。 例えば、\(\mathcal{X} = \{A, B, C\}\) としたとき、\(2^\mathcal{X} = \{ \emptyset, \{ A \}, \{ B \}, \{ C \}, \{ A, B \}, \{ A, C \}, \{ B, C \}, \{ A, B, C \} \}\)です。 さて、ここで、\(2^\mathcal{X}\)の要素全てに対して何か処理をしたいときを考えましょう。 それはプログラミングとしてどう記述すればよいでしょうか?実はこのように部分集合の列挙を簡潔に書くのは簡単ではありません。 ここでビット演算の登場です。整数の各桁を集合の要素だと考えます。ここで「整数に1を足す」という処理をよく考えると、それは 可能な組み合わせを列挙していることと同じだと気付きます。 よって、「冪集合の要素の列挙」は、「要素数分のビットに対し、インクリメントを行う」と同じです。これを元に列挙を行ったのが次です。
int n = 3; // 要素は3つ
// 0b00000000 <= b < 0b00001000 の区間をイテレーションする
for (unsigned char b = 0; b < (1 << n); ++b) {
printf("b: ");
print_bit_uchar(b);
printf("{");
if (b & 0b00000001) { // 右から0番目にビットが立っていたら「A」
printf("A, ");
}
if (b & 0b00000010) { // 右から1番目にビットが立っていたら「B」
printf("B, ");
}
if (b & 0b00000100) { // 右から2番目にビットが立っていたら「C」
printf("C, ");
}
printf("}\n");
}
b: 00000000
{}
b: 00000001
{A, }
b: 00000010
{B, }
b: 00000011
{A, B, }
b: 00000100
{C, }
b: 00000101
{A, C, }
b: 00000110
{B, C, }
b: 00000111
{A, B, C, }
こういった、ビットを扱う処理をビットトリックと呼んだりします。 黒魔術とも言える様々な難解ビットトリックが世の中には存在します。 こちらなどを見ると色々と載っています。日本語の記事ではこちらが非常にわかりやすいです。
やってみよう(30分)
上記を写経してみましょう
クイズ
- ビット単位の和を計算する
&と、論理演算子の&&を間違えないようにしましょう。同様に、|と||を間違えないようにしましょう。 これらは別者ですが、時として同じ値になることがあるので、注意が必要です。以下の場合を考えましょう。unsigned char i = 1; unsigned char j = 0;とき、上記の4演算を試すとどうなるでしょうか。unsigned char i = 3; unsigned char j = 3;とき、上記の4演算を試すとどうなるでしょうか。
- ハミング距離のコードを書いてみましょう。ハミング距離とは、二つのビット列が与えられたときに、各桁について、値が同じなら0、違えば1、として、それをまとめたものです。
ここでは、ビット列の長さは8とします。
まずはビット演算ではなく、
intの配列として考えてみましょう。以下のような関数hamming_dist_array(int x1[], x2[])を考えてくださいint v1[8] = {0, 0, 1, 0, 0, 1, 1, 0}; int v2[8] = {0, 1, 0, 0, 1, 0, 1, 0}; int d = hamming_dist_array(v1, v2); // 4になる - 次に、8桁のビット列を
unsigned charで表しましょう。これに対するハミング距離計算の関数hamming_dist(unsigned char c1, unsigned char c2)を書いてみましょう。ヒント:まず各桁における値の差異を求め、それを最後に集計すればよいです。unsigned char v1 = 0b00100110; unsigned char v2 = 0b01001010; int d = hamming_dist(v1, v2); // 4になる - 最後に、
hamming_distを高速化するアイデアを考えてみてください。
答え
- 以下のようになります。
- 最初の例では、ビット演算と論理演算では同じになります
unsigned char i = 1; unsigned char j = 0; printf("%d\n", i & j); // 0 printf("%d\n", i && j); // 0 printf("%d\n", i | j); // 1 printf("%d\n", i || j); // 1 - 二つ目の場合は、ビット演算と論理演算で結果が違います。
unsigned char i = 3; unsigned char j = 3; printf("%d\n", i & j); // 3 printf("%d\n", i && j); // 1 printf("%d\n", i | j); // 3 printf("%d\n", i || j); // 1
- 最初の例では、ビット演算と論理演算では同じになります
- 例えば以下のようになります。
int hamming_dist_array(int x1[], int x2[]) { int d = 0; for (int i = 0; i < 8; ++i) { if (x1[i] != x2[i]) { ++d; } } return d; } - 例えば以下のようになります。
int popcount(unsigned char a) { // a中に出現する1の回数をカウントする // K&R, p62 int cnt; for(cnt = 0; a != 0; a >>= 1) { if (a & 1) { ++cnt; } } return cnt; } int hamming_dist(unsigned char c1, unsigned char c2) { unsigned char diff = c1 ^ c2; // まずはXORで差分を一気にもとめる return popcount(diff); // そのうち、1が出現している回数を数える } - 一つの例は、
popcountを高速化することです。popcountは入力としてunsigned charを取ります。unsigned charは256通りの整数しか表現できないので、あらかじめ全ての結果のパターンを計算しておき、 表として持っておくことができます。計算時にはその表を見に行くことで、高速にpopcountを実行できます。 まず次のような表を事前に用意しておきます。そして、次のように// この表は「ビットを数える・探すアルゴリズム」から引用 // http://www.nminoru.jp/~nminoru/programming/bitcount.html int count_table[256] = { 0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8, };popcountを変更すればOKですさて、このpopcountという処理は重要な処理なので、これまでに多くの計算方式が考えられてきました。 例えば先ほどのビットトリック集のCounting bits setというところを見ると色々書いてありますので、眺めてみると面白いです。 そして、このpopcountの機能はハードウェア上で実装されている場合もあります。その場合、例えばGCCがそのハードウェアを直接扱う関数を 準備していたりします(int popcount_table(unsigned char a) { return count_table[a]; }int __builtin_popcount (unsigned int x))。これを使うと、上記のように アルゴリズムで高速化するよりも、速いです。
ライブラリツアー¶
Cでは講義で扱わなかった様々な便利関数があります。それらは適切なファイルをincludeすると使えるようになります。以下に見てみましょう。
これらのファイルの詳細はたとえばこういうところを見ると書いてあります。
数学関数:math.h¶
math.hをincludeすると、様々な数学関数が使えます。
math.hを使う場合、コンパイル時に、gcc -lm main.cのように-lmオプションが必要かもしれません。
printf("PI: %f\n", M_PI); // 3.141593 円周率が定義されています
printf("cos(PI): %f\n", cos(M_PI)); // -1 コサイン
printf("exp(3): %f\n", exp(3.0)); // 20.085537 exp
printf("pow(3.0, 2.0: %f\n", pow(3.0, 2.0)); // 9.000000 累乗
printf("sqrt(9.0): %f\n", sqrt(9.0)); // 3.000000 ルート
printf("fabs(-2.5): %f\n", fabs(-2.5)); // 2.500000 絶対値
整数値の限界:limits.h¶
limits.hをインクルードすると、整数値の限界に関する情報を入手することが出来ます。
たとえばINT_MINという表記で、int型がとりうる最小値を知ることが出来ます。
printf("INT_MIN = %d\n", INT_MIN); // -2147483648
printf("INT_MAX = %d\n", INT_MAX); // 2147483647
小数に関する情報:float.h¶
float.hをインクルードすると、小数に関する情報を入手することが出来ます。
たとえばFLT_MINという表記で、float型がとりうる最小値を知ることが出来ます。
printf("FLT_MIN = %e\n", FLT_MIN); // 1.175494e-38
printf("FLT_MAX = %e\n", FLT_MAX); // 3.402823e+38
文字判定:ctype.h¶
ctype.hをインクルードすると、文字に関する様々な関数
が使えるようになります。
// アルファベットかどうかの判定
printf("isalpha('a'): %d\n", isalpha('a')); // 1024 非0の値になる
printf("isalpha('3'): %d\n", isalpha('3')); // 0
// 数字かどうかの判定
printf("isdigit('a'): %d\n", isdigit('a')); // 0
printf("isdigit('3'): %d\n", isdigit('3')); // 2048 非0の値になる
ローレベルなメモリコピー:string.h¶
string.hをincludeすると文字列に対する様々な関数が使えることは既に述べました。
それ以外にも、ローレベルで直接配列をコピーするものがあります。
char src[] = {'a', 'b', '\0', 'c', 'd'};
char dst1[10];
char dst2[10];
// 文字列のコピー。'\0'が出るところまでをコピー
strcpy(dst1, src); // 'a', 'b', '\0'
// 文字列に限らない、任意のメモリ分量のコピー
// 三番目の引数はコピーする`char`の個数
memcpy(dst2, src, 5); // 'a', 'b', '\0', 'c', 'd'
警告:assert.h¶
assert.hには、警告に関する関数が含まれます。
これは、次のように、「必ずある条件を満たしてほしい」ということを示すために使います。
int N = 10;
int a[N];
int n = getchar();
n -= '0';
// assertの中身が真であれば何もしない。偽であればエラーになる。
// この場合、キーボードから入力された文字がN未満の数字であればOK
assert(0 <= n && n < N);
a[n] = 123;
printf("a[%d]: %d\n", n, a[n]);
乱数、system:stdlib.h¶
stdlib.hには様々な機能があることを既に勉強してきましたが、
乱数も扱うことができます。
乱数とは、その名の通りランダムな数です。
ここではrand()関数によりランダムなintが返ります。
また、取りうる値の最大値としてRAND_MAXも準備されているため、
それで割ることで疑似的に0 - 1のレンジの乱数も作れます。
ここでsrand(seed)というのは、乱数の種(seed)を与えるものです。
疑似乱数生成器は同じseedに対しては同じ乱数列を与えます。
このseedを同じにすれば、乱数であっても結果が再現できます。
srand(123);
for (int n = 0; n < 4; ++n) {
printf("%d\n", rand());
}
// 128959393
// 1692901013
// 436085873
// 748533630
for (int n = 0; n < 4; ++n) {
double r = (double) rand() / RAND_MAX;
printf("%f\n", r);
}
// 0.361609
// 0.134639
// 0.375968
// 0.259322
また、システムに関する関数も準備されています。
例えばsystem(cmd)関数はcmdをターミナルから実行したものと同じことをする関数です。
これは危険なのであまり使わないほうがいいです。
system("ls"); // ターミナルでlsと打った時とおなじように、現在のディレクトリのファイルを表示
やってみよう(15分)
上記を写経してみましょう
宿題¶
それでは今週の宿題です。
- 締切は次の授業の前日の深夜23:59までです(今回の場合、2021/11/17, 23:59)
- 宿題リンクをslackで配付します。このリンクは公開しないでください。
week6_1¶
疎行列とベクトルの積を計算しましょう。疎行列とは、要素の多くが0である行列のことです。 線形代数により何かを処理する際、行列が疎になるこということは極めてよくあります。 例えば、グラフ構造を行列として表現しようとすると、多くの場合疎な行列になります。 よって、疎行列をどう表現するか、疎行列による計算をどう行うかについて、様々な研究が取り組まれてきました。
今回の宿題では、疎行列を表現する最も基本的な形式であるCompressed sparse row (CSR)形式を実装しましょう。 以下のような疎行列\(\mathbf{A} \in \mathbb{R}^{D \times D}\) を考えます。ここで\(D=4\)とします。
これを素朴に密行列として表そうとすると、要素が\(T\) byteで表されるとして少なくとも\(TD^2\) byteのメモリ領域を消費します。 これはいつも通りなので嬉しくありません。 ここでは実は、\(\mathbf{A}\)は疎行列なので、非ゼロの要素数が少ないという情報をもちいて、以下のように3つの配列を用いて効率的に表現できます。
まず、行列を左から右、上から下に舐めていき、非ゼロの要素が出現したときに(1) その要素 (2) 何列目か (3) 何行目か を記録していきます。これにより次のような配列が出来ます。
v: [13, 24, 31, 11, 44, 71]
col_idx: [ 2, 0, 1, 3, 2, 3]
row_idx: [ 0, 1, 1, 1, 3, 3]
vに\(TN\)、およびidxに\(2N\)個の整数分のメモリしか使用しません。定義より\(N\)は小さいため、これは元の密行列よりもずっとデータ効率のいい表現形式だと言えます。
さらに、構成より、row_idxは数字が連続することが分かります。ここを、次のような規則で作るcompressed_row_idxという配列で置き換えます。
compressed_row_idxの0番目の要素は0compressed_row_idxの\(i\)番目の要素は、「compressed_row_idxの\(i-1\)番目の要素」と「row_idx中で\(i-1\)が登場した回数」の和
この規則により作られるものが以下です。
compressed_row_idx: [ 0, 1, 4, 4, 6]
v, col_idx, compressed_row_idxの3つのみを保存すればOKということになります。
上記の3つの配列から、もとの要素を復元するにはどうすればいいでしょう?\(\mathbf{A}\)の\(j\)行目の値を復元するには、
compressed_row_idx[j] <= n < compressed_row_idx[j + 1]
v[n], col_idx[n]を引っ張ってくればOKです。
例えば、元の行列のj=1行目の値は24 31 0 11ですが、これは次のように求まります。
compressed_row_idx[1] = 1, compressed_row_idx[2] = 4
1 <= n < 4
col_idx[1] = 0, v[1] = 24
col_idx[2] = 1, v[2] = 31
col_idx[3] = 3, v[3] = 11
さて、そのような疎行列を設計しましょう。まずはmain.cを読み、中身を理解してください。メイン関数の中は編集しないでください。コンパイルはいつも通りgcc main.cです。
課題1¶
ここでは、DxDの整数値を扱う密行列の構造体であるDenseIntMat、およびD次元の整数の縦ベクトル DenseIntVecが定義されています。
まずは練習がてら、DenseIntMatとDenseIntVecの行列積を実行する関数mul_dmat_dvecを埋めてください。これにより、実行結果は以下のようになります。
./a.out smat1.txt
[20,
9,
21,
11,
25, ]
課題2¶
次に、整数の疎行列SparseIntMatを考えます。上記をCSR方式を参考に、疎行列に値をセットする関数であるset_smat, および内容をプリントするprint_smatを埋めてください。
ここでは簡単のため、本来の定義とは少し外れて、非ゼロの個数の最大値はMAX_SIZEに定義されているとします。
この最大値以上の要素をもつ疎行列は考えなくて大丈夫です。結果は以下のようになります。
./a.out smat1.txt
[20,
9,
21,
11,
25, ]
[0, 0, 1, 0, 3,
5, 3, 0, 9, 0,
0, 0, 1, 0, 0,
0, 0, 8, 0, 0,
1, 0, 0, 0, 2, ]
課題3¶
最後に、疎行列と密ベクトルの行列積であるmul_smat_dvecを埋めてください。これにより、結果は以下のようになります。
./a.out smat1.txt
結果は以下です。
[20,
9,
21,
11,
25, ]
[0, 0, 1, 0, 3,
5, 3, 0, 9, 0,
0, 0, 1, 0, 0,
0, 0, 8, 0, 0,
1, 0, 0, 0, 2, ]
[7,
38,
1,
8,
5, ]
自動採点では、smat2.txtを使うパターンも用意しています。